This the multi-page printable view of this section. Click here to print.
Developer Guide
- 1: Creating and Configuring Your First FX Service
- 2: FX Core Lib: Simplifying FX Service Development
- 3: Deploy a Service
- 4: Project and Code Structure
- 5: Secrets
- 6: State Management
- 7: Form Generator
- 8: Database Integration
- 9: Event Source Adapters
- 10: Extending the Platform
- 11: Git Integration
- 12: Event Manipulation Strategies
- 13: Logging and Monitoring
1 - Creating and Configuring Your First FX Service
Creating and Configuring Your First FX Service in a Local Environment
No Infrastructure Required!
When it comes to developing FX services, there’s no need for complex infrastructure setups. Nearly all of the platform’s essential features can be replicated in your local development environment.This guide provides a clear walkthrough of the process for creating and simulating services, all within the comfort of your desktop IDE. By following these steps, you’ll be able to seamlessly generate and define services, and then simulate their behavior before taking them live.
Step 1: Create a Virtual Environment
Before you start working on your FX service, it’s a good practice to create a virtual environment to isolate your project’s dependencies. A virtual environment ensures that the packages you install for this project won’t conflict with packages from other projects. You can create a virtual environment using a tool like virtualenv:
|
|
Activate the virtual environment:
|
|
Step 2: Set Environment Variable
Set the EF_ENV environment variable to “local” to indicate that you’re working in a local development environment:
|
|
Step 3: Project Directory Setup
Create a directory that will serve as the main project directory. Inside this directory, you will organize multiple services. For example:
|
|
Step 4: Create Service Directory
Within the project directory, create a subdirectory for your specific service. This directory should have a name that consists of alphanumeric characters in lowercase, along with underscores (_) and hyphens (-) – no spaces allowed:
|
|
Step 5: Create app.py
Inside the service directory, create an app.py file. This file will serve as the entry point for your FX service. In this file, import the necessary context from the fx_ef (core library) for your service:
|
|
Step 6: Run app.py
Run the app.py file. This step generates two JSON files:
ef_env.json: Simulates the parameters, secrets, and configurations of the service.ef_package_state.json: Holds the execution state of the service.
The above 2 files are used to simulate the service environment and are not used at runtime. They should not be checked in to git. A sample .gitignore for FX projects is provided here The GitIgnore File
|
|
Step 7: Expand Your Service
With the initial setup done, you can now expand the app.py file with your actual service logic. Build and implement your FX service within this file.
Step 8: Module Placement
It’s important to note that any modules (additional Python files) your service relies on should be placed within the same directory as the app.py file. FX does not support nested directories for modules.
By following these steps, you’ll be able to create your first FX service in a local environment, set up the necessary configurations, and start building your service logic. Remember to activate your virtual environment whenever you work on this project and customize the app.py file to match the functionality you want your FX service to provide.
Adding a manifest.json file to describe your FX service to the platform is an essential step for proper integration and communication. Here’s how you can create and structure the manifest.json file:
Step 9: Create manifest.json
Inside your service directory, create a manifest.json file. This JSON file will contain metadata about your service, allowing the FX platform to understand and interact with it.
|
|
"name": Provide a name for your FX service."version": Specify the version of your FX service (e.g., “1.0.0”)."description": Add a brief description of what your service does."author": Add your name or the author’s name."entry": Point to the entry point of your service (usuallyapp.py)."configuration": Reference theef_env.jsonfile that holds service parameters, secrets, and configurations."executionState": Reference theef_package_state.jsonfile that holds the execution state of the service."modules": List the modules that your service relies on. In this case, it’s just"app.py".
Step 10: Manifest Structure
The manifest.json file provides vital information about your FX service, making it easier for the platform to understand and manage your service’s behavior and dependencies.
By including this file and its necessary attributes, your service can be properly registered, tracked, and executed within the FX platform. This manifest file essentially acts as a contract between your service and the platform, enabling seamless integration.
Understanding manifest.json: Defining Your Service
The manifest.json file plays a crucial role in describing your application to the DX Platform, as well as to fellow users and developers. Below is a sample manifest.json file along with an explanation of its parameters:
manifest.json Example:
|
|
Parameters and Descriptions:
| Parameter | Description |
|---|---|
description |
A brief description of the service. |
entrypoint |
The script that will be executed when the service is triggered. |
execution_order |
An array indicating the sequence of scripts to be executed. If both entrypoint and execution_order are defined, entrypoint will be used. |
tags |
An array of tags that categorize the service. |
trigger_events |
An array of events that will trigger the service’s execution. |
schedule |
Optional. A cron-like definition for scheduling service executions. |
allow_manual_triggering |
Indicates whether the service can be triggered manually. |
active |
Indicates whether the service is active or inactive. |
This manifest.json file provides essential metadata about your service, making it easier for both the platform and other users to understand its purpose, behavior, and triggers. By customizing these parameters, you tailor the service’s behavior to your specific requirements.
Feel free to integrate this explanation into your documentation. Adapt the content to match your documentation’s style and format. This section aims to provide users with a comprehensive understanding of the manifest.json file and its significance in defining FX services.
Step 11: Expand ef_env.json
The ef_env.json file plays a crucial role in simulating your service’s environment during development. While on the FX platform, parameters, configs, and secrets are managed differently, in the local environment, you can define these elements within this JSON file for simulation purposes.
|
|
-
"parameters": In the local environment, you can define parameters directly within this dictionary. These parameters are typically accessed within your service code using thefx_eflibrary. -
"secrets": Similarly, you can define secret values in this section. While on the platform, secrets will be managed through the UI and loaded into your service securely. During local simulation, you can include sample secret values for testing. -
"configs": For configuration values, you can specify them in this dictionary. However, on the FX platform, configuration values are usually managed through an externalconfig.jsonfile. This is done to keep sensitive configuration data separate from your codebase.
Important Note: Keep in mind that the ef_env.json file is only for simulation purposes. On the FX platform, parameters are passed through trigger event payloads, configurations come from the config.json file, and secrets are managed through the platform’s UI.
By expanding your ef_env.json file with the appropriate parameters, secrets, and sample configuration values, you’ll be able to effectively simulate your service’s behavior in a local environment. This allows you to test and refine your service logic before deploying it on the FX platform, where parameters, secrets, and configurations are handled differently.
Step 12: Exploring the fx_ef Library
In the following section, we’ll delve into the capabilities of the ferris_ef library. This library serves as a bridge between your FX service and the platform, allowing you to seamlessly implement various platform features within your service’s logic.
The fx_ef library encapsulates essential functionalities that enable your service to interact with the FX platform, handling triggers, events, and more. By leveraging these features, you can create robust and responsive FX services that seamlessly integrate with the platform’s ecosystem.
Here’s a sneak peek at some of the functionalities offered by the fx_ef library:
-
Event Handling: The library facilitates event-driven architecture, allowing your service to react to various triggers from the platform. Whether it’s an incoming data event or an external signal, the library provides the tools to manage and respond to events effectively.
-
Parameter Access: While on the FX platform, parameters are passed through trigger event payloads. The library offers methods to access these parameters effortlessly, enabling your service to make decisions and take actions based on the provided inputs.
-
Configuration Management: Although configuration values are typically managed through a separate
config.jsonfile on the platform, thefx_eflibrary simplifies the process of accessing these configurations from within your service code. -
Secrets Handling: On the platform, secrets are managed securely through the UI. The library ensures that your service can access these secrets securely when running on the platform.
-
Service State Tracking: The library also assists in managing your service’s execution state, tracking its progress and ensuring smooth operation.
By tapping into the capabilities of the fx_ef library, you can build powerful and versatile FX services that seamlessly integrate with the FX platform’s functionalities. In the next section, we’ll dive deeper into the specifics of how to utilize these features in your service logic.
Stay tuned as we explore the fx_ef library in depth, unraveling the tools at your disposal for creating impactful and responsive FX services.
Feel free to adapt this content to your documentation’s style and structure. It’s designed to introduce users to the significance of the fx_ef library and prepare them for a deeper dive into its features and usage.
2 - FX Core Lib: Simplifying FX Service Development
FX Core Lib: Simplifying FX Service Development
The FX Helper package, available through the fx_ef library, offers an array of convenient functions that streamline the development of FX services. This guide walks you through the different ways you can leverage this package to access service configurations, parameters, secrets, and state within your service logic.
Accessing Package Configuration
Retrieve configuration values that influence your service’s behavior by using the context.config.get() method:
|
|
Accessing Execution Parameters
Access parameters that affect your service’s execution using the context.params.get() method:
|
|
Accessing Secrets
Easily access secrets stored on platform, project, or package levels with the context.secrets.get() method:
|
|
Setting Secrets
Set secrets on project and platform levels using the context.secrets.set() method:
|
|
Accessing Package ID and Name
Retrieve your package’s ID and name using the context.package.id and context.package.name attributes:
|
|
Accessing and Updating Package State
Manage your service’s execution state with context.state.get() and context.state.put():
|
|
Logging
Leverage logging capabilities at different levels - DEBUG, INFO (default), ERROR, WARNING, and CRITICAL:
|
|
Scheduling Retry of Service Execution
Use the context.scheduler.retry() method to schedule the next execution of your service from within your script:
|
|
This guide provides insight into the powerful functionalities offered by the fx_ef library, making FX service development more efficient and intuitive. These tools empower you to create responsive and feature-rich FX services with ease.
3 - Deploy a Service
Deploying Services: A Step-by-Step Overview
In this section, we provide you with a concise yet comprehensive overview of the steps required to deploy a service or a collection of services onto the FX platform. Following these steps ensures a smooth transition from development to deployment.
Step 1: Check Services into Git
Before anything else, ensure your collection of services is properly versioned and checked into a Git repository. This guarantees version control and a reliable source of truth for your services.
Step 2: Create a Project in the UI
In the FX platform UI, initiate the process by creating a project. Projects serve as containers for your services, aiding in organization and management.
Step 3: Add Git Repository to the Project
Once your project is in place, seamlessly integrate your Git repository with it. This connection allows the platform to access and manage your services’ source code.
Step 4: Sync the Repository to the Platform
The final step involves syncing the repository you’ve connected to your project with the FX platform. This synchronization imports the services’ code, configurations, and other relevant assets into the platform environment.
By following these four fundamental steps, you’re well on your way to deploying your services onto the FX platform. Each of these steps plays a vital role in ensuring that your services are seamlessly integrated, accessible, and ready for execution within the FX ecosystem.
Detailed Deployment Process: From Git to FX Platform
This section breaks down the steps outlined earlier for deploying services onto the FX platform in detail, starting with checking services into Git.
Check Services into Git
Since familiarity with Git is assumed, we’ll briefly touch on this step. Within the FX platform, each directory within a Git Repository represents a distinct service. Files placed directly in the root directory of a Repository are not considered part of any service.
Create a Project in the UI
Creating Projects and Linking with Git Repository:
-
Create a New Project:
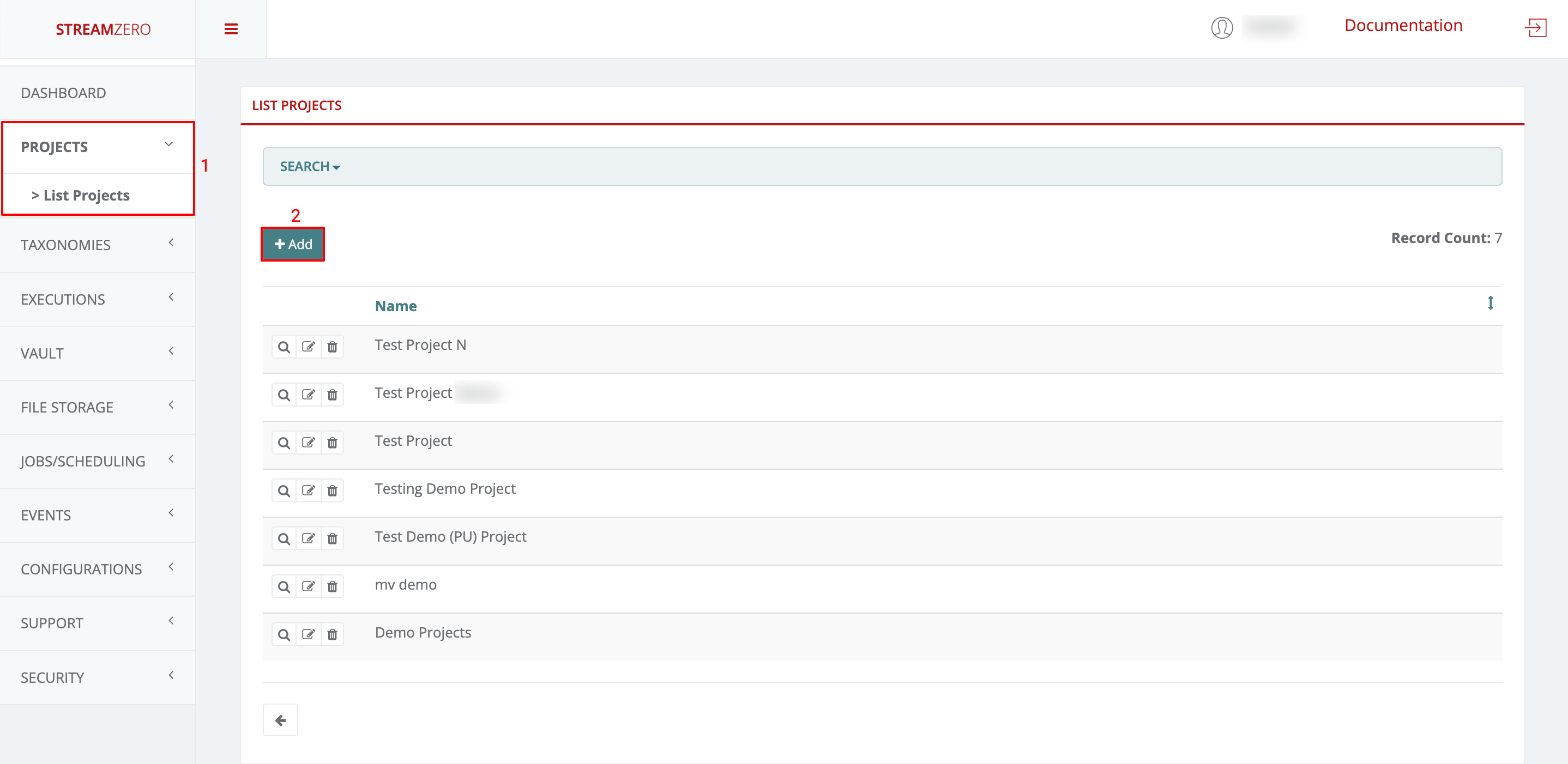
- Navigate to the “Projects” section on the left menu, then select “List Projects.”
- Click “+Add” to create a new project.
-
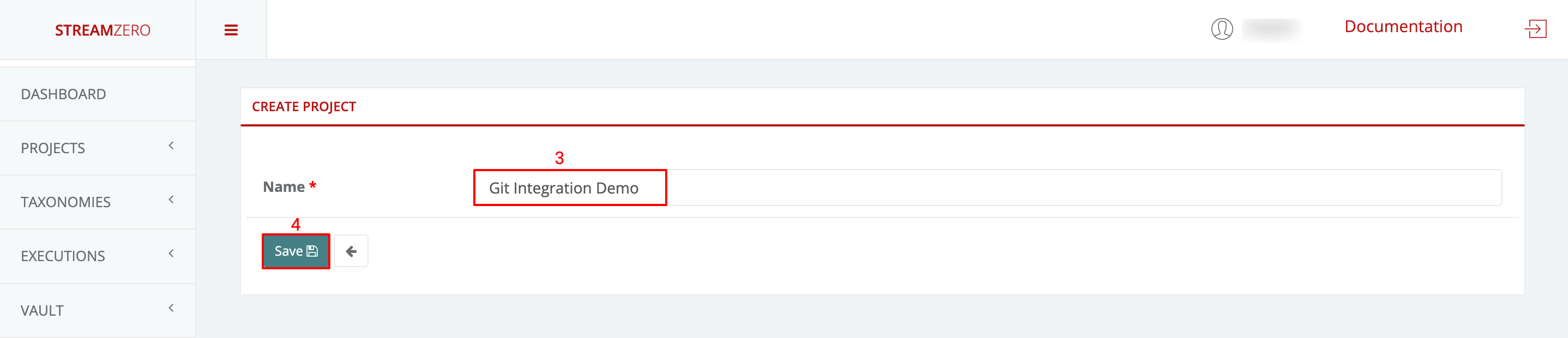
Name the Project:
- Provide a name for the project.
- Save the project.
-
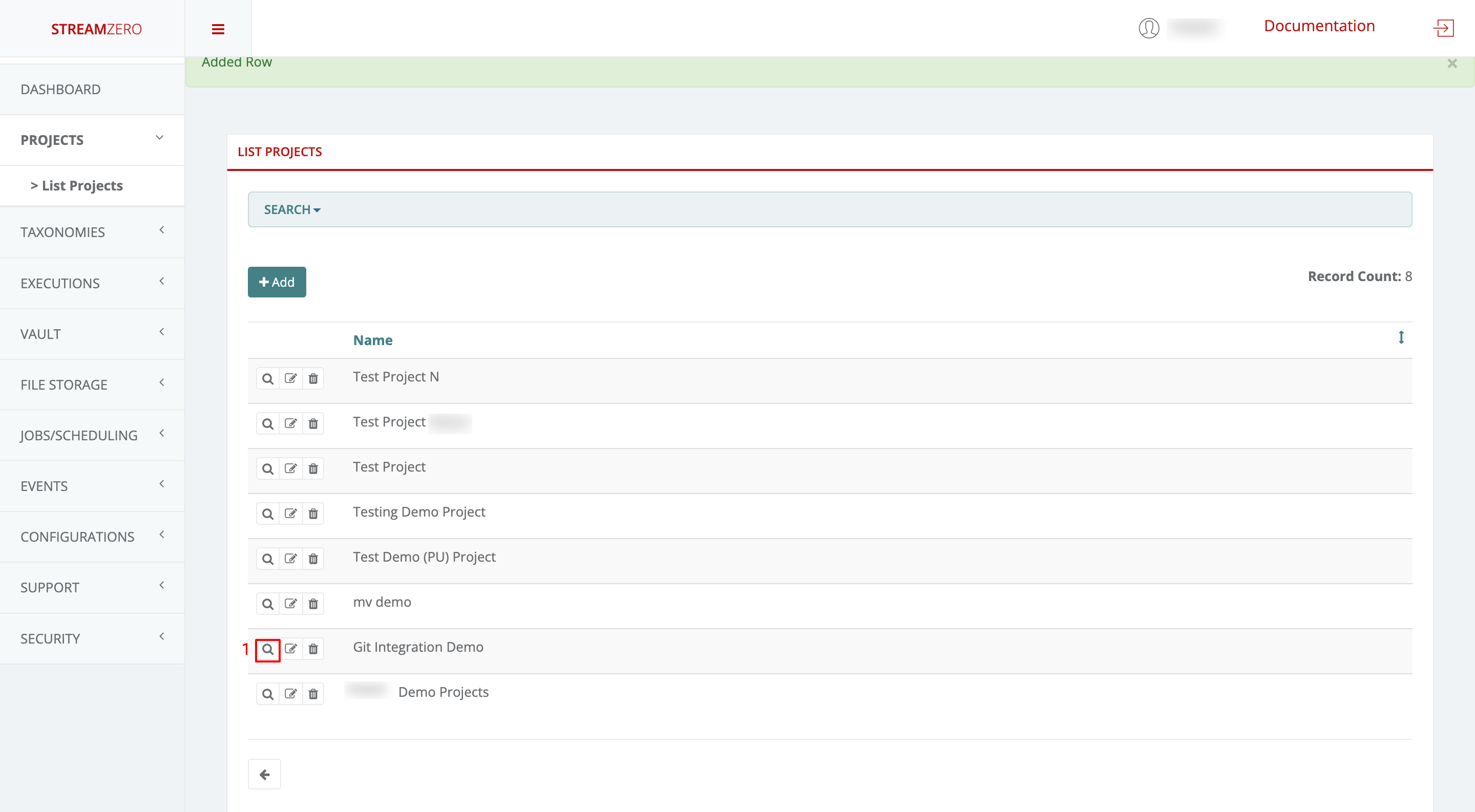
View Project Details:
- Click the magnifying glass icon to access the project’s details page.
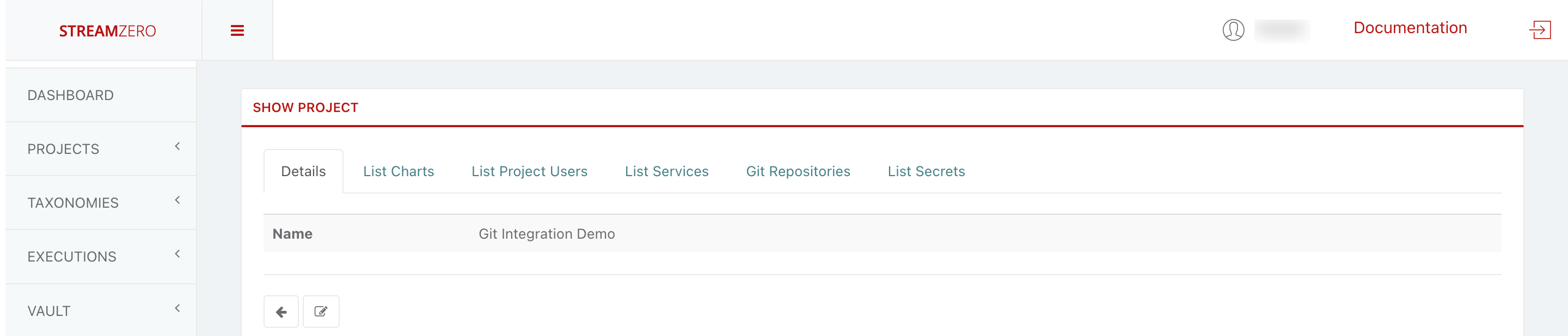
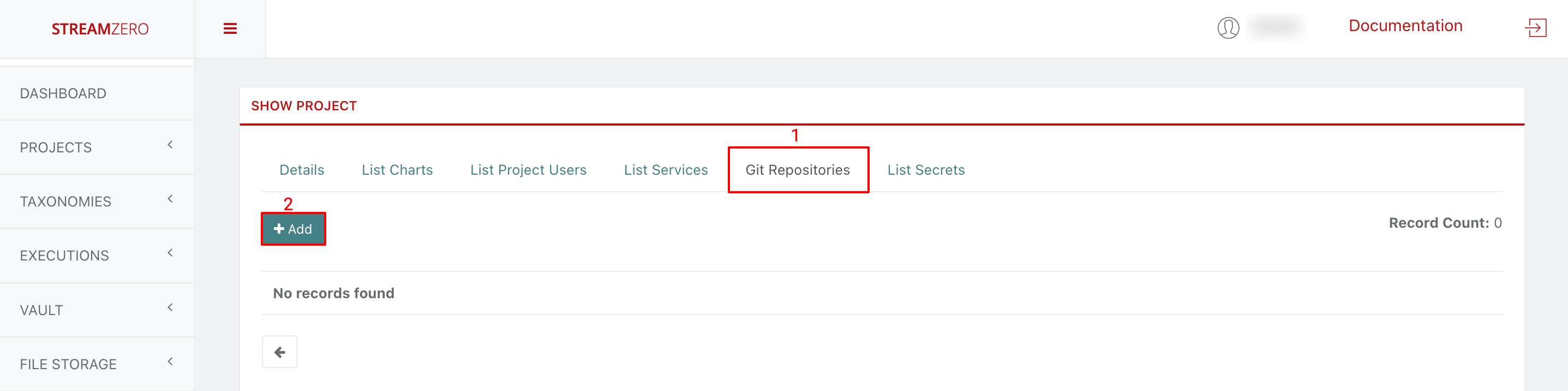
- Add a GitHub Repository:
- Access the “Git Repositories” tab.
- Click “+Add” to add an SSH repository URL.
- Copy GitHub Repo:
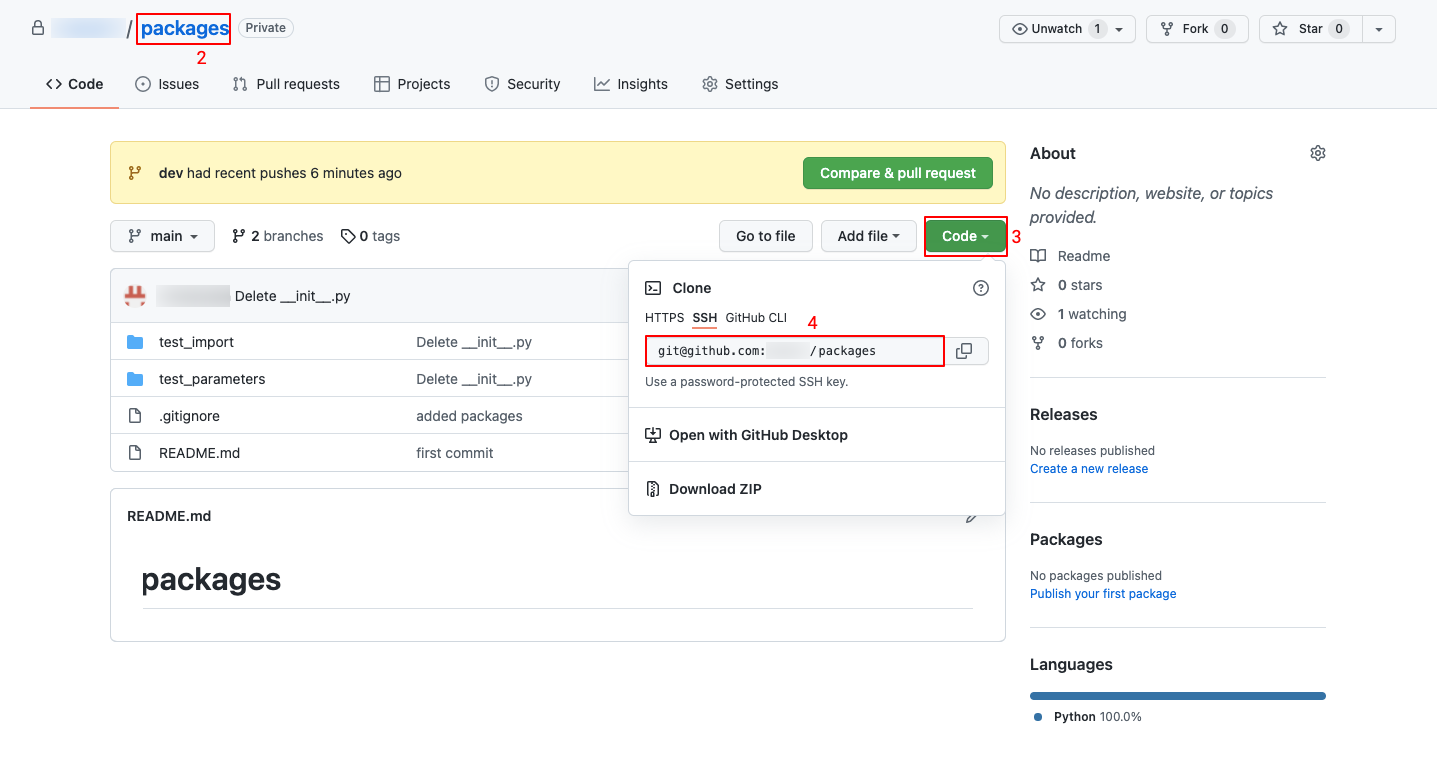
- Generate a public SSH key (if not done previously).
- Login to your GitHub account.
- Go to the repository you want to link.
- Click the green “Code” button to reveal repository URLs.
- Copy the SSH URL.
-
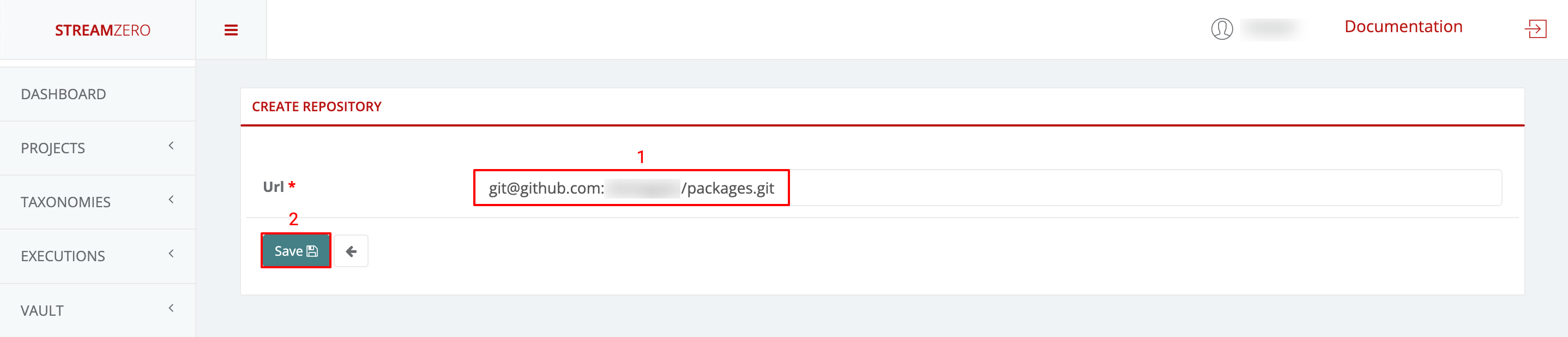
Paste SSH URL:
- Paste the copied SSH URL into the platform.
- Save to set up the repository.
- A pop-up will display a platform-generated public key. This key should be added to the GitHub Repo’s Deploy Keys to enable syncing.
-
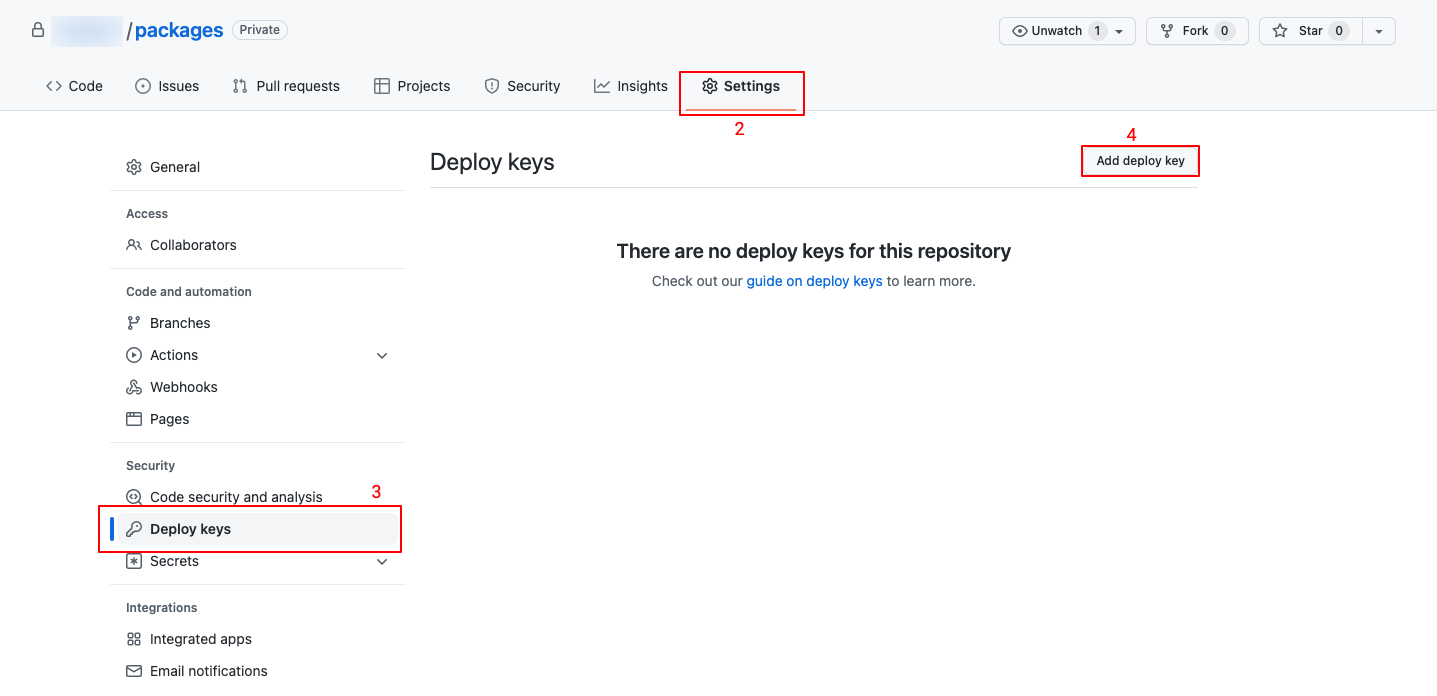
Add Public Key to GitHub:
- Return to GitHub.
- Go to Settings > Deploy Keys.
- Click “Add Deploy Key.”
- Paste the generated public key, name it, and add the key.
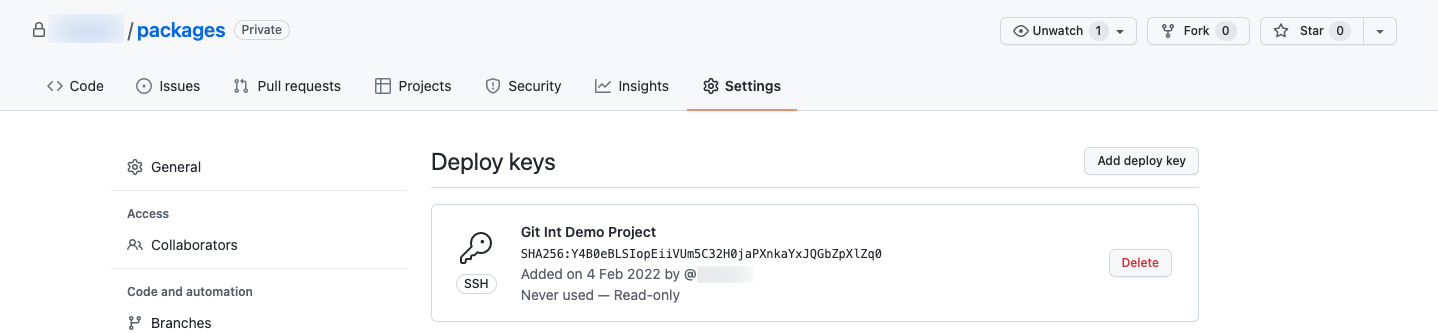
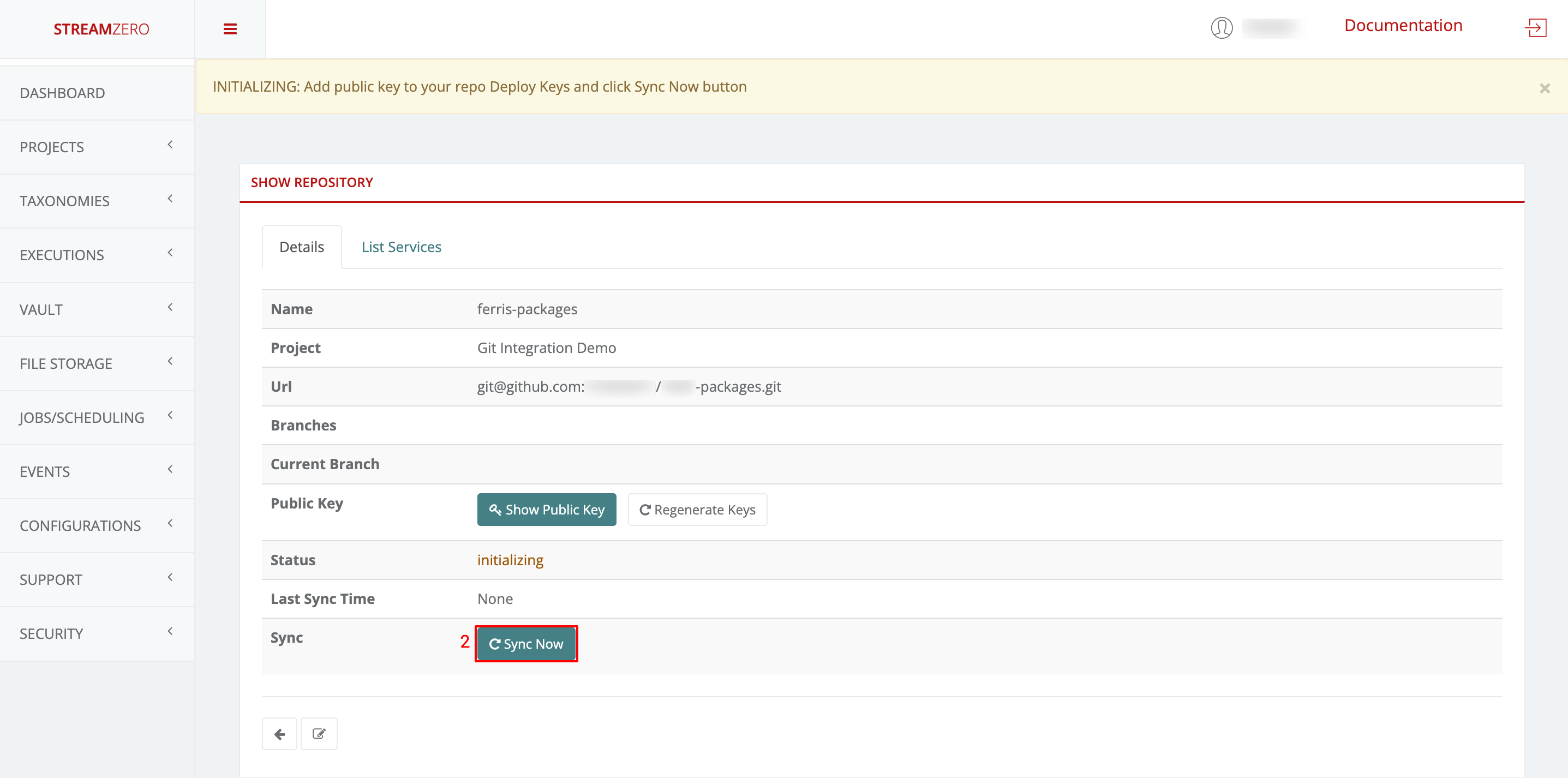
- Synchronize the Repository:
- Return to the FX platform.
- Click “Sync Now” to sync the platform with the Git Repository.
- Check the synchronized details page; branches will be added, and status changes.
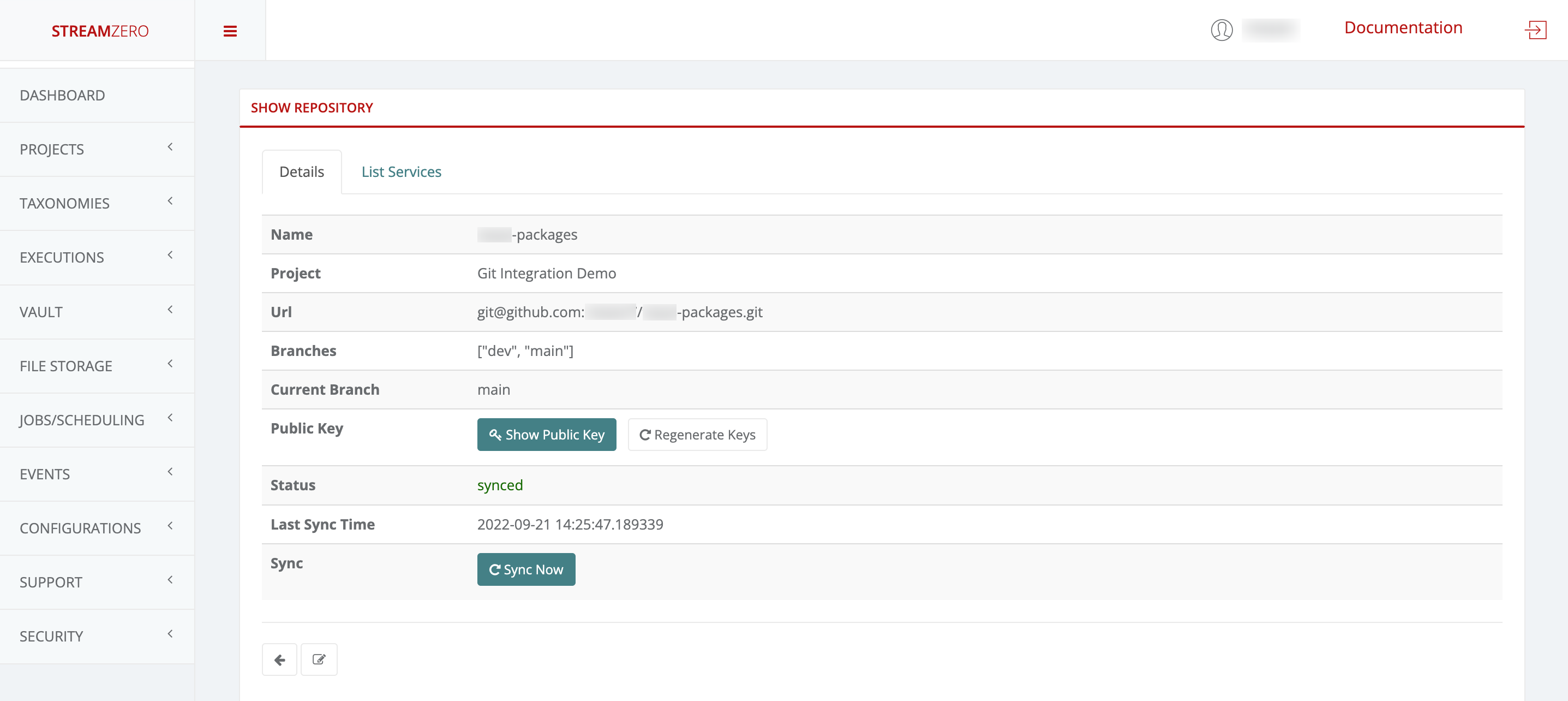
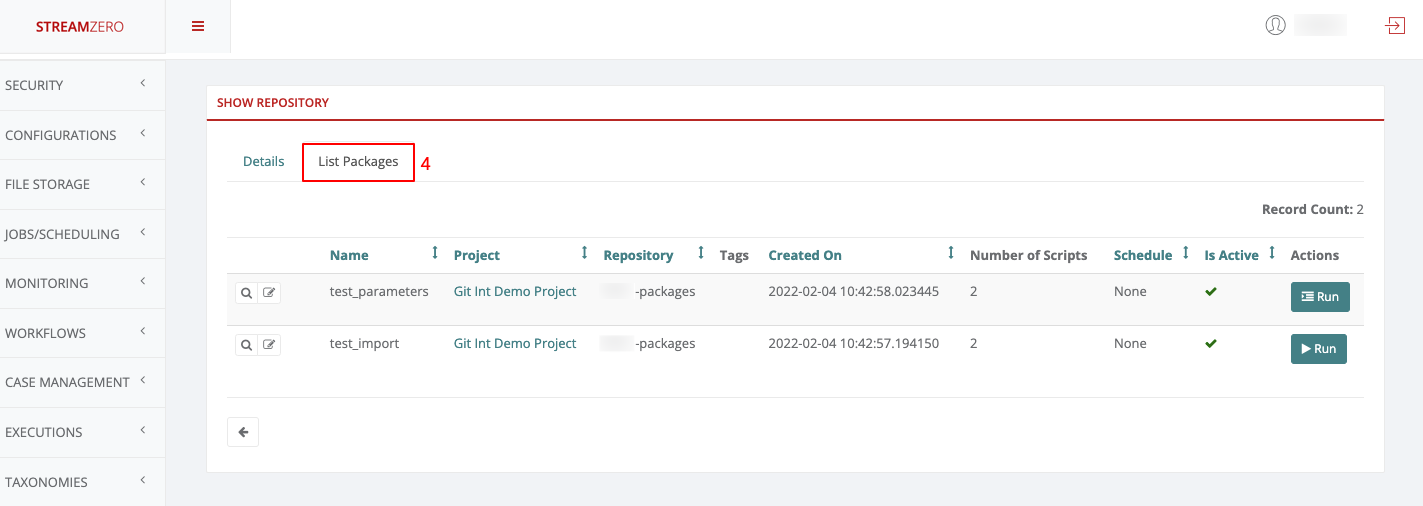
- Check the Synced Packages:
- Verify imported packages by clicking the “List Packages” tab.
- Note that the main branch is automatically synchronized. As development continues and multiple branches are used, they can also be synced individually.
- Change Git Branch on the Platform:
- Users can choose a specific branch to work on or test.
- Access the Edit Repository details page.
- Select the desired branch from the dropdown (e.g., “dev”).
- Save the selection and synchronize packages.
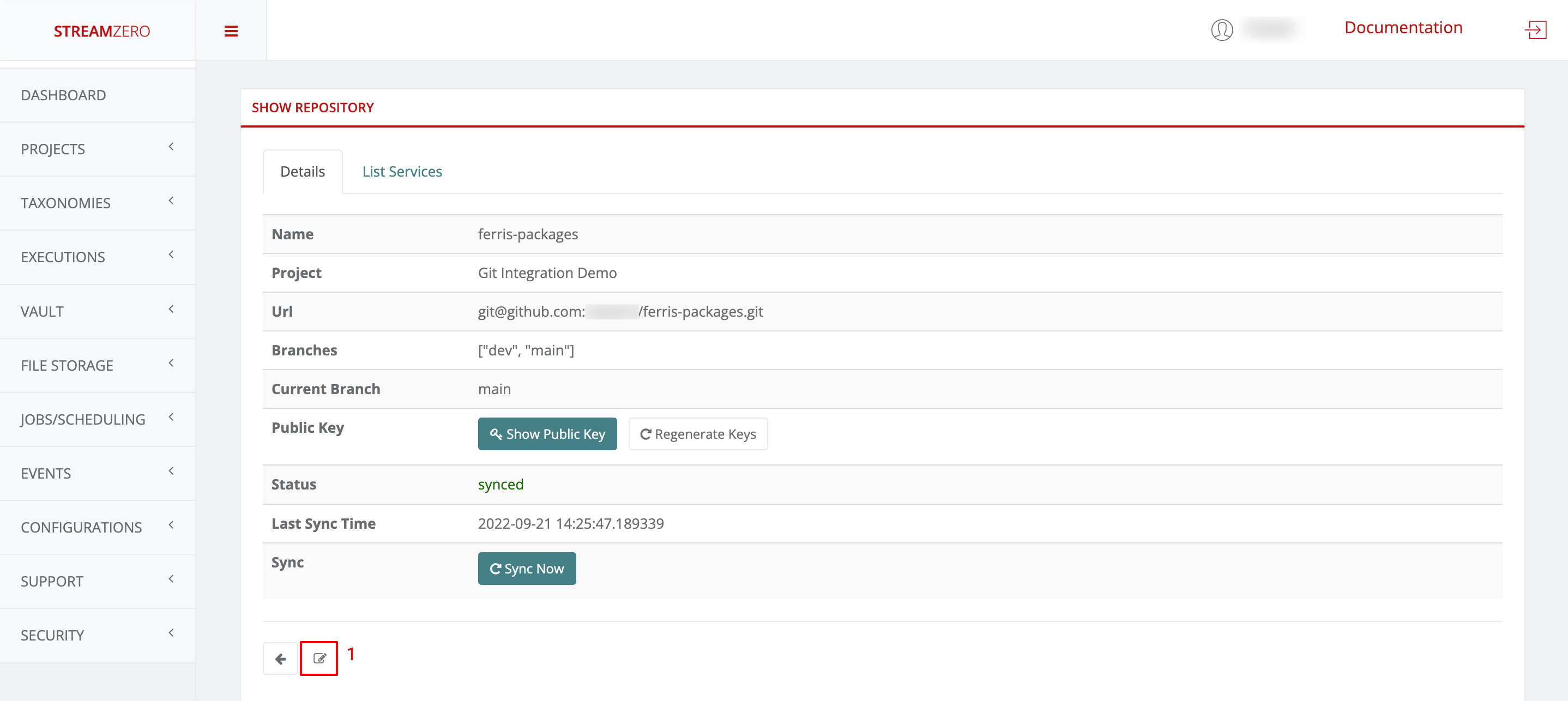
- Verify Synced Packages on Dev Branch:
- Check the “List Packages” tab to confirm successful synchronization from the dev branch.
Managing Public Keys for Security and Access
It’s important to understand the dynamics of managing public keys to ensure security and controlled access within the FX platform environment. Here’s a breakdown of key considerations:
-
Regenerating Public Keys:
- You can regenerate a public key at any time if there’s a concern that unauthorized access might have occurred.
- Regenerated keys must be added to GitHub again and synchronized on the platform afterward.
-
Ensuring Synchronization:
- Whenever a new public key is generated, it must be added to the respective GitHub repository.
- Failure to complete this step will result in synchronization issues on the platform.
-
Synchronization and Key Addition:
- When generating a new key, add it to GitHub’s Deploy Keys.
- Afterward, ensure the key is synchronized on the platform to maintain access.
-
Revoking Access:
- If a situation arises where platform access should be revoked, keys can be deleted directly on GitHub.
The meticulous management of public keys is essential for maintaining the security and integrity of your FX services. By being proactive in regenerating keys, properly adding them to GitHub, and ensuring synchronization on the platform, you’re taking steps to uphold a secure development and deployment environment.
Integrate these insights into your documentation, adapting the content to match your documentation’s tone and style. This note aims to provide users with a clear understanding of how to manage public keys effectively within the FX platform ecosystem.
4 - Project and Code Structure
In this section, we’ll delve into the structure and components that make up an FX service. Understanding the organization of services, repositories, and the various artefacts involved is pivotal for efficient development within the FX platform.
Understanding Projects
Within the FX Platform, a Project serves as a container for multiple Services. Projects don’t play a functional role; they primarily aid in organizing services based on functional relationships, solution domains, or user access groups.
A project can be associated with multiple git repositories, each containing a collection of services.
Repository Structure
In the DX platform, every directory within a Repository represents a distinct service. Files located in the root directory of a Repository are disregarded.
Service Artefacts
A service encompasses an assortment of scripts, modules, and assets, including configuration files. The following are the supported types of artefacts along with their respective roles:
| Artefact Type | Description |
|---|---|
*.py |
Python scripts form the core of a service. You can include multiple python scripts, and they are executed in the order defined in the manifest.json file. These scripts can define classes, static methods, and more. |
*.sql |
SQL files containing SQL statements. They are executed against the default database defined in the platform. These files support a ‘jinja’ like notation for parameter extraction and embedding program logic within the SQL. |
manifest.json |
The manifest.json file serves to describe the service to the platform and other users. It adheres to a predefined structure and is detailed further in the ‘Manifest File’ section. |
config.json |
This JSON file defines the service’s configuration. These values are stored in Consul once imported into the platform. Configuration values can be accessed using the service’s ‘context’ with the ferris_ef module. |
secrets.json |
This file outlines the secrets accessible within a specific service. The secrets.json file is uploaded via the UI and should not be committed to Git. |
*.txt, *.json, *.jinja, etc. |
Various assets utilized by the service. |
parameters.json |
Optional. This file defines MicroUIs, which generate forms to trigger a service. |
Understanding the components that constitute a service, repository, and project sets the foundation for effective FX service development. With this knowledge, you can seamlessly create, organize, and manage your services within the DX platform.
Sample Repository and Directory Structure
|
|
5 - Secrets
Secrets are sensitive configuration information which you wish to use within your service. These may be a single attribute(such as a password) structures with multiple attributes.
Secrets are the ability to deal with sensitive data through scripts (secrets.json) needed for package execution, such as:
- Database Passwords
- Secret Keys
- API Keys
- any other sensitive data
Secrets aren’t visible to any users and are passed encrypted to the actual script at the predefined package execution time. Once the script (secrets.json) is uploaded to the platform, the data is read and securely (double encryption) stored in the database.
Secret Scopes
The DX platform supports the following scopes for a secret.
| Scope | Description |
|---|---|
| Service secrets | Service Scope secrets are only available to the specific service within which the secret was defined. They are managed by uploading a secrets.json file on the service management UI. While they can also by synced from GIT, this is not a preferred approach in order to avoid having secrets in git. |
| Project Secrets | Secrets that are accessible to any service within a specific project. These are created by uploading a JSON file on the project secrets tab on the UI. |
| Platform Secrets | Secrets that are accessible to any service running on the platform. These are created by uploading JSON file on the Vault->Secrets page. |
When accessing secrets using fx_ef.context.secrets.get('secret_name') it will first lookup for secret_name within service secrets, then project and finally platform
The secrets.json File
To add service scope secrets you can upload a secrets.json file.
Those values are stored double encrypted in database and can be only accessed within the executing script. A sample secrets.json
|
|
Accessing secrets
With fx_ef.context.secrets you can access secrets stored on at the platform, project or service scope.
|
|
This command will first lookup for secret named secret_name within package secrets (defined in secrets.json file of the package). If such key doesn’t exist it will lookup for it within project secrets, and finally within platform’s secrets. If secret with such name doesn’t exist None will be returned.
Can be accessed using fx_ef.context.secrets.get('secret_name'). Can be set using context.secrets.set(“secret_name”, {“somekey”:“someval”}, “project”)`
Can be accessed using fx_ef.context.secrets.get('secret_name'). Can be set using context.secrets.set("secret_name", {"somekey":"someval"}, "platform")
Setting secrets
Using fx_ef.context.secrets.set(name, value, context) method you can set secrets on project and platform level.
|
|
| Parameter | Description |
|---|---|
| name | Name of the secret to be set. If secret with the same name already exist it will be updated |
| value | Value of the secret that should be set |
| context | Context of the secret. Possible values are platform and project |
Create a new package
Note that the package creation was presented in another submenu of the User Guide, so only the needed parameters will be filled in the package to showcase the Secrets functionality.
-
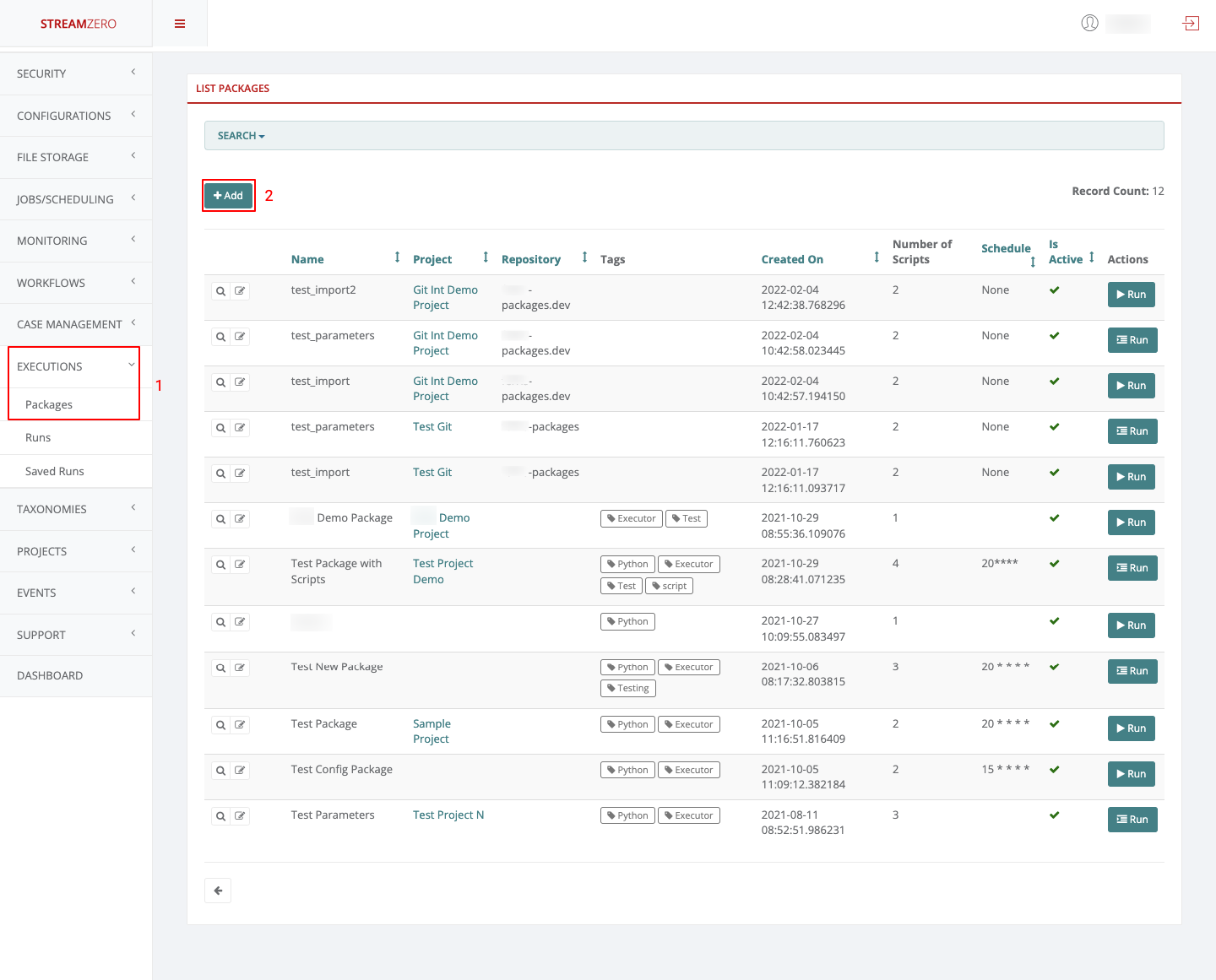
Click on Executions in the left side menu and on Packages
-
Click on Add to create a new package
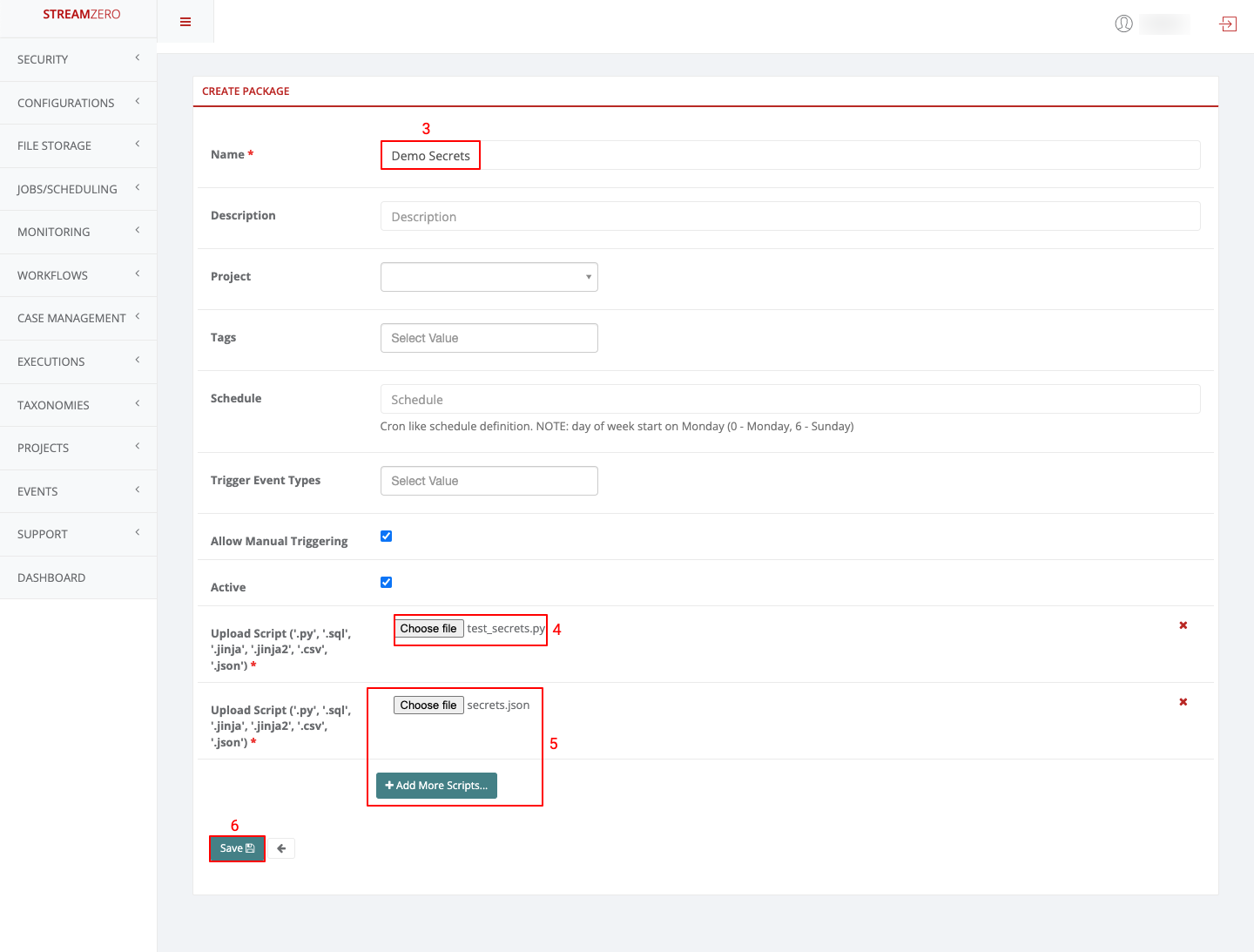
- Name the package
- Click on choose file and add the python scrypt (test_secrets.py)
- Click on Add more scripts and click on choose file to add the JSON script (secrets.json)
- Click on Save to save the package
test_secrets.py script
This is an example script that shows how secrets from the secrets.json file can be accessed from a script at execution time using the get_secret() helper function from the fx_ef package.
|
|
6 - State Management
One key aspect in reactive applications is how to manage state between runs.
With StreamZero FX this is simple. Each Service has a state object available at run time. All you need to do is the following.
|
|
The state is stored across Service runs. A state log is also maintained and stored for reference and reload.
How it works
When a Service is started the state is loaded from the consul key store.
When a state is stored it is placed in Consul as well as sent to Kafka. The Kafka stream maintains an audit log of the state. And also serves to retreive state after a system shut down.
7 - Form Generator
Occasionally you will come across use cases where you are required to provide a frontend for trigerring a service - usually by a non-technical person. FX and K8X both provide the ability to define Forms using a simple JSON structure.
The Forms are generated automatically by the StreamZero Management UI based on the ‘parameters.json’ file.
When a service directory contains a parameters.json file the ‘Run’ Button on th Management UI will automatically change the icon to a ‘Form’ icon.
The parameters.json file can be added to an existing service directory. When doing so you need to ensure that within the manifest.json file the ‘allow_manual_trigerring’ is set to ’true’
The following is a template for a parameters.json file.
The parameters.json file
The parameters.json file contains a JSON definition of fields that will be rendered and presented to user upon manually triggering a package execution in order to gather the parameter values for running the package. This way, same package can be easily adapted and reused by different scenarios or environments simply by sending different parameter values to the same package.
|
|
The above template will display a form which looks as below.
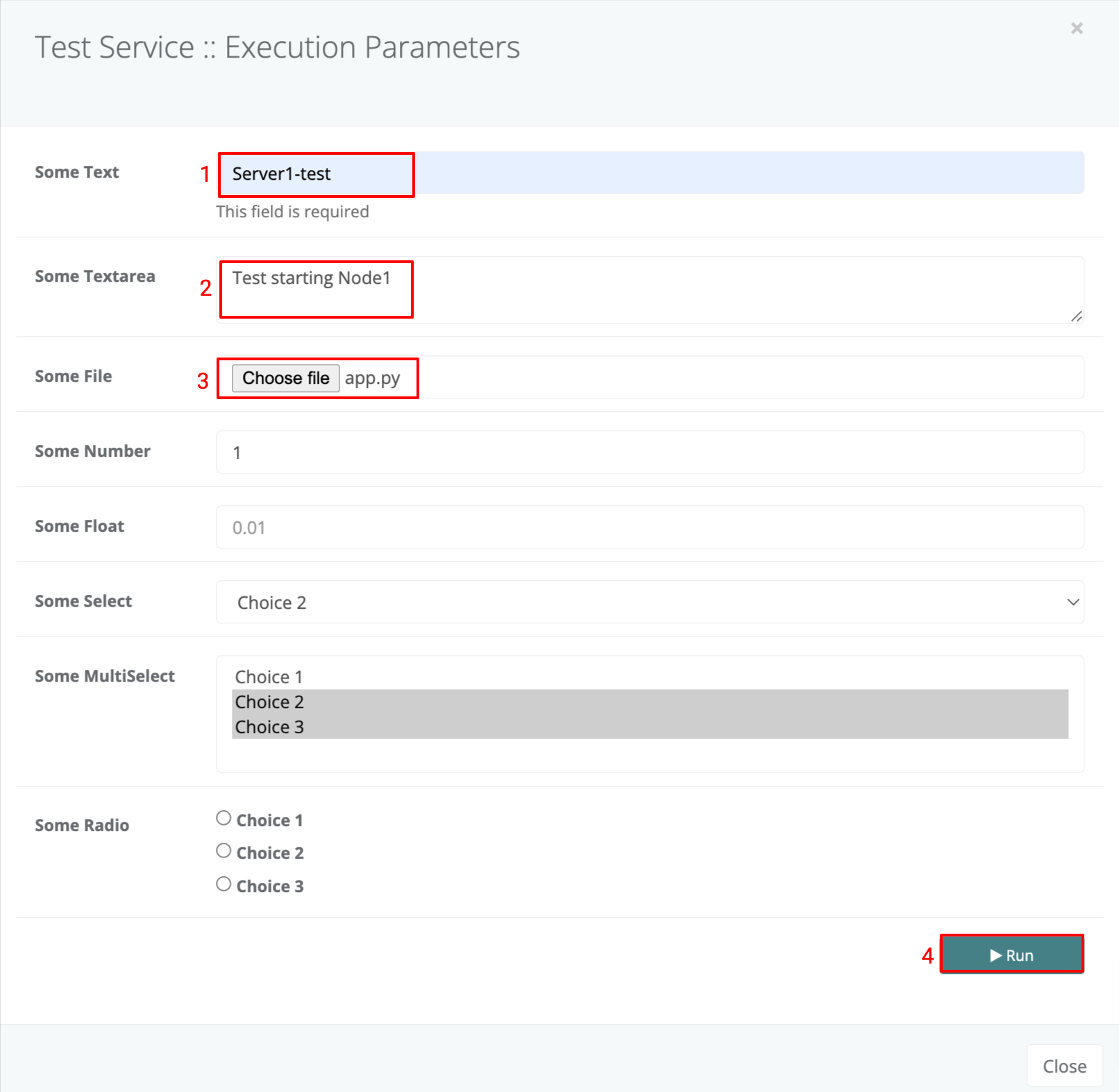
When the form values and entered and the ‘Run’ Button is clicked the form parameters and values will be sent to the service on trigger and these will be available to the service just as if it were trigerred by an event with the same payload as the form values.
The following is a sample script that extracts the parameters (you will notice it is no different from an event trigerred script). The only exception are the text areas which are dealt with as String data type and therefore should be converted using the relevant JSON library.
|
|
8 - Database Integration
Install Database Drivers
StreamZero DX requires a Python DB-API database driver and a SQLAlchemy dialect to be installed for each datastore you want to connect to within the executor image.
Configuring Database Connections
StreamZero can manage preset connection configurations. This enables a platform wide set up for both confidential as well as general access databases.
StreamZero uses the SQL Alchemy Engine along with the URL template based approach to connection management. The connection configurations are maintained as secrets within the platform and are therefore not publicly accessible i.e. access is provided for administrators only.
Retrieving DB Connections
The following is how to retrieve a named connection. The following sample assumes that the connection identifier key is uploaded to the package as a secrets.json.
|
|
In the above example the db_url is set up as a secret with name 'my_connection'.
Depending on whether this is a service, project or platform level secret there are different approaches to set up the secret. For service level secret the following is a sample set up for a secrets.json file of the package.
|
|
- For Project scope use the
'secrets'tab of the Project Management UI. - For Platform scope secrets use the
Vault UIin the DX Manager Application.
Database Drivers
The following table provides a guide on the python libs to be installed within the Executor docker image. For instructions on how to extend the Executor docker image please check this page: /docs/extending_executor_image
You can read more here about how to install new database drivers and libraries into your StreamZero DX executor image.
Note that many other databases are supported, the main criteria being the existence of a functional SQLAlchemy dialect and Python driver. Searching for the keyword “sqlalchemy + (database name)” should help get you to the right place.
If your database or data engine isn’t on the list but a SQL interface exists, please file an issue so we can work on documenting and supporting it.
A list of some of the recommended packages.
| Database | PyPI package |
|---|---|
| Amazon Athena | pip install "PyAthenaJDBC>1.0.9 , pip install "PyAthena>1.2.0 |
| Amazon Redshift | pip install sqlalchemy-redshift |
| Apache Drill | pip install sqlalchemy-drill |
| Apache Druid | pip install pydruid |
| Apache Hive | pip install pyhive |
| Apache Impala | pip install impyla |
| Apache Kylin | pip install kylinpy |
| Apache Pinot | pip install pinotdb |
| Apache Solr | pip install sqlalchemy-solr |
| Apache Spark SQL | pip install pyhive |
| Ascend.io | pip install impyla |
| Azure MS SQL | pip install pymssql |
| Big Query | pip install pybigquery |
| ClickHouse | pip install clickhouse-driver==0.2.0 && pip install clickhouse-sqlalchemy==0.1.6 |
| CockroachDB | pip install cockroachdb |
| Dremio | pip install sqlalchemy_dremio |
| Elasticsearch | pip install elasticsearch-dbapi |
| Exasol | pip install sqlalchemy-exasol |
| Google Sheets | pip install shillelagh[gsheetsapi] |
| Firebolt | pip install firebolt-sqlalchemy |
| Hologres | pip install psycopg2 |
| IBM Db2 | pip install ibm_db_sa |
| IBM Netezza Performance Server | pip install nzalchemy |
| MySQL | pip install mysqlclient |
| Oracle | pip install cx_Oracle |
| PostgreSQL | pip install psycopg2 |
| Trino | pip install sqlalchemy-trino |
| Presto | pip install pyhive |
| SAP Hana | pip install hdbcli sqlalchemy-hana or pip install apache-Feris[hana] |
| Snowflake | pip install snowflake-sqlalchemy |
| SQLite | No additional library needed |
| SQL Server | pip install pymssql |
| Teradata | pip install teradatasqlalchemy |
| Vertica | pip install sqlalchemy-vertica-python |
| Yugabyte | pip install psycopg2 |
9 - Event Source Adapters
The Event Source Adapter enables easy integration of external event streams to Ferris.
The role of the Event Source Adapter is to receive events from external streams, convert them into Cloud Events and push them to the ferris.events Kafka Topic. The Cloud Events that are generated will contain an indicator of the source, one or more specific event types (depending on the type of source and the use case) and the content of the source event in the payload of the output Cloud Event.
Example Event Source Adapters
The following are a couple of examples of source adapters
Generic Webhook Adapter : Exposes a webhook end point outside the cluster which may be used to submit events as webhook requets. The generic adapter may source multiple event types and does not filter the content. It may be used for example to simultaneously accept AWS EventBrige CouldEvents and GitHub Webhooks. It is the role of a package to filter or split events as is suited for the use case.
Twitter Adapter: Streams twitter based on configured hash tags and converts them to cloud events.
IBM MQ Adapter
Kafka Adapter: Sources data from JSON streams within kafka and converts them to Cloud Events.
Azure MessageBus Adapter:
Amazon SQS Adapter
MQTT Adapter
Redis Queue Adapter
ActiveMQ Source
Amazon CloudWatch Logs Source
Amazon CloudWatch Metrics Sink
Amazon DynamoDB Sink
Amazon Kinesis Source
Amazon Redshift Sink
Amazon SQS Source
Amazon S3 Sink
AWS Lambda Sink
Azure Blob Storage Sink
Azure Cognitive Search Sink
Azure Cosmos DB Sink
Azure Data Lake Storage Gen2 Sink
Azure Event Hubs Source
Azure Functions Sink
Azure Service Bus Source
Azure Synapse Analytics Sink
Databricks Delta Lake Sink
Datadog Metrics Sink
Datagen Source (development and testing)
Elasticsearch Service Sink
GitHub Source
Google BigQuery Sink
Google Cloud BigTable Sink
Google Cloud Functions Sink
Google Cloud Spanner Sink
Google Cloud Storage Sink
Google Pub/Sub Source
HTTP Sink
IBM MQ Source
Microsoft SQL Server CDC Source (Debezium)
Microsoft SQL Server Sink (JDBC)
Microsoft SQL Server Source (JDBC)
MongoDB Atlas Sink
MongoDB Atlas Source
MQTT Sink
MQTT Source
MySQL CDC Source (Debezium)
MySQL Sink (JDBC)
MySQL Source (JDBC)
Oracle Database Sink
Oracle Database Source
PagerDuty Sink
PostgreSQL CDC Source (Debezium)
PostgreSQL Sink (JDBC)
PostgreSQL Source (JDBC)
RabbitMQ Sink
RabbitMQ Source Connector
Redis Sink
Salesforce Bulk API Source
Salesforce CDC Source
Salesforce Platform Event Sink
Salesforce Platform Event Source
Salesforce PushTopic Source
Salesforce SObject Sink
ServiceNow Sink
ServiceNow Source
SFTP Sink
SFTP Source
Snowflake Sink
Solace Sink
Splunk Sink
Zendesk Source
Generic Webhook Adapter
The Edge Adapter exposes a single endpoint for Webhooks. The webhook may be used for a large number of incoming integrations. Some examples are provided below.
To see the API please visit webhook.edge.YOURDOMAIN.COM/ui . For example webhook.edge.ferris.ai .
In order to use the end point you must first generate a token to be used when submitting to the endpoint. To generate a token please follow instructions here ….
How it Works
The StreamZero Edge Adapter is an edge service which is exposed to services outside the network for incoming integrations with external services. It exposes a single token protected endpoint which accepts a JSON payload within a POST request.
The payload encapsulated within the POST is forwarded to the ferris.events topic with the data encapsulated in the Cloud Events ‘data’ section. The event type is ‘ferris.events.webhook.incoming’ .
The platform may host any number of packages which then process the webhooks based on parsing the data section.
The StreamZero Edge Adapter is one of the few services exposed to the Internet.
Integrations
The following sections document details on some of the possible integrations.
AWS EventBridge
AWS S3 ( please switch images)
A pre-requisite is to ensure that EventBridge is sending Events to Ferris. Please see this section on how to set it up.
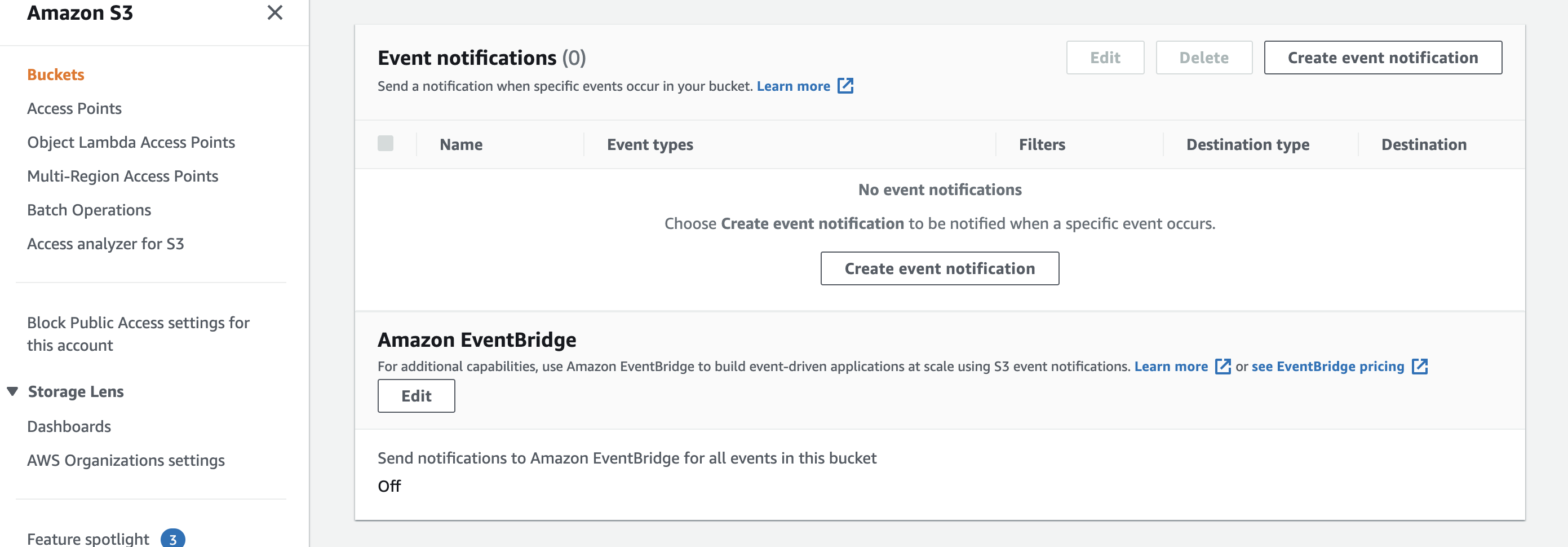
Create a bucket and switch to the Properties Tab of the UI

Scroll to the bottom and turn on Event Bridge Notfications by clicking on the Edit button below the section Amazon EventBridge
GitHub Integration
To be notified on changes to a Git Hub Repo please follow the steps below.
Click on the ‘Settings’ icon for the repo
Select the Webhooks menu on the left of the ‘Settings’ page. Then click on the ‘Add webhook’ button.
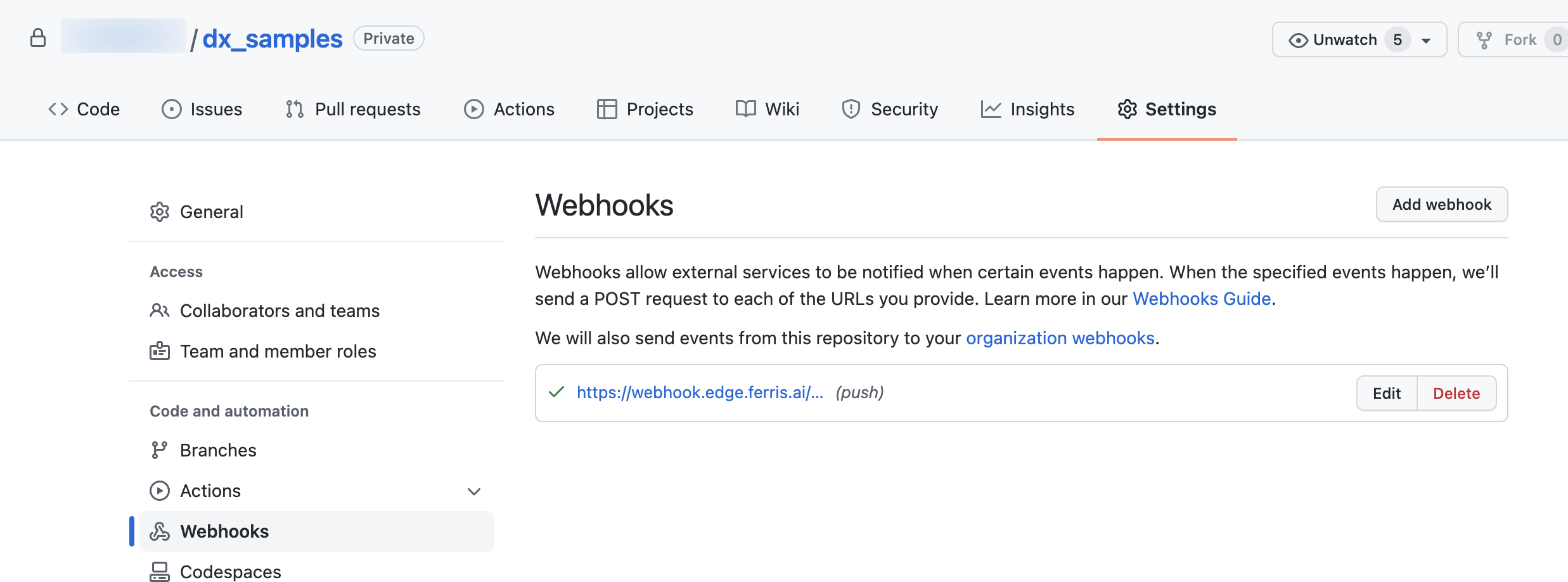
Add the URL of your edge adapter end point. And ensure the content type is application/json. Finally add the api token generated on the StreamZero Management UI. Further in the page you may select what event types should be sent. If unsure please maintain the default settings.
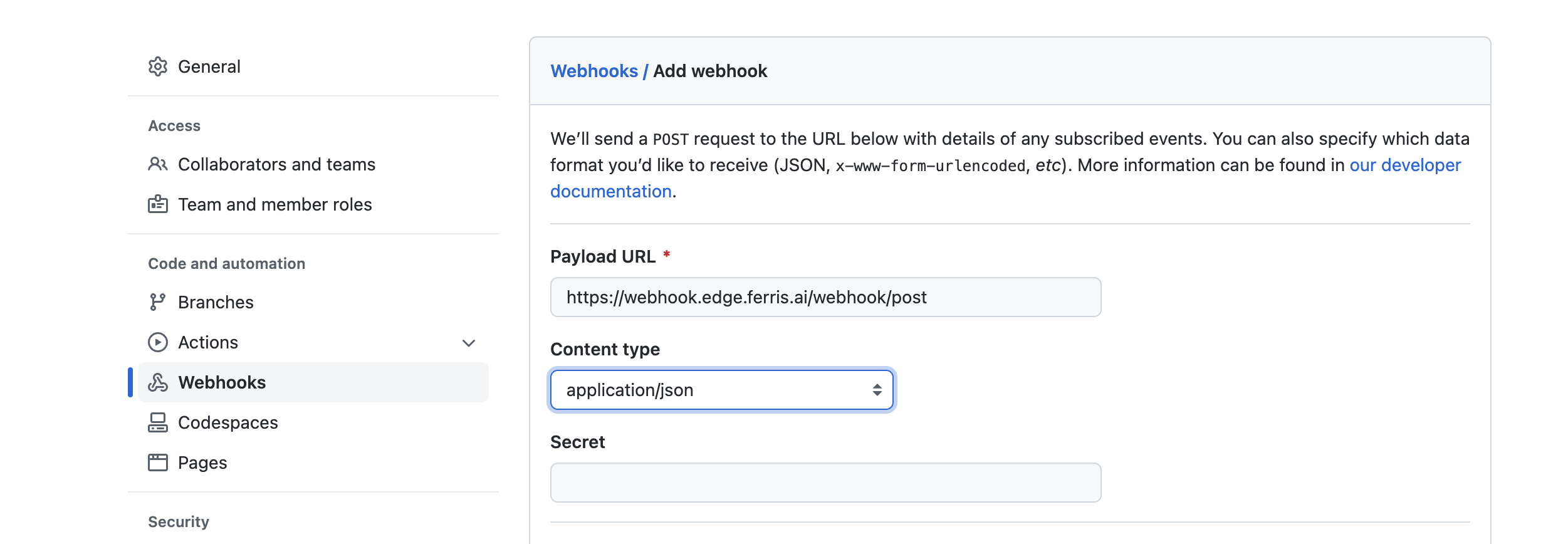
Test your integration by pushing an update to the repository.
10 - Extending the Platform
Extending the Platform
The platform may be extended at 3 logical points within the event life cycle.
- At Entry Point:
- They are respnsible for injecting external event streams into the platform. Primarily they mediate betweeen the exrernal event stream and the internal CloudEvents based Kafka Topics. These run on separate containers within the platform. The following are the typical examples.
- Event Gateway: are the primary mechanism. To build event gateways we provide templates. Please check this document on extension.
- They are respnsible for injecting external event streams into the platform. Primarily they mediate betweeen the exrernal event stream and the internal CloudEvents based Kafka Topics. These run on separate containers within the platform. The following are the typical examples.
- At Processing
- These are extensions that operate on internal event streams or are required by services that are created on the platform. The following are the types thereof.
- Configuration Adapters and UIs. These are primarily used for connection setups and configurations which are applicable across the platform. Examples are the variety of connection set up UIs we provide. They are very easy to create. Use the the followinng guide to build your own.
- Python Libraries and Modules: These are attached to the executor. It primarily involves extending the executor image with the required library. In order to add them to the platform use this guide.
- Event Processing Packages: These are services that only modify event attributes normally convert one type of event to another. These can be implemented as services within the platform. Please see following guide to see how they are used and some typical scenarios.
- No Code Generators: Generators combine UI based with templated code to allow No Code based approach to creating services. Please check this guide on how that works.
- These are extensions that operate on internal event streams or are required by services that are created on the platform. The following are the types thereof.
- At Exit Point
- These are primarily modules that interact with external systems but operate across the example. The primarily operate on streams that originate from the platform and mediate with the outside. These run on separate containers within the platform. The following are typical implementaions. Examples are
- Protocol Adapters They adapt between the internal kafka even streams and external protocols for example webhook adapter, Kafka to imbm mq adapter etc. Their primary purpose is to offload activity from the platform which may cause bottle necks or require long running services.
- Splitters and Filters: These may operate on strams to split content or event infromation into derivative streams. Or feed data into supporting infrastructure. The elastissearch and Splunk adapters are typical examples. In order to build these use the following guide and related templates.
- These are primarily modules that interact with external systems but operate across the example. The primarily operate on streams that originate from the platform and mediate with the outside. These run on separate containers within the platform. The following are typical implementaions. Examples are
11 - Git Integration
The Git Integration is the capability to generate a connection from a git repository with projects and synchronise the Packages from the Executor with the git repository, with the goal to execute it through the StreamZero FX Platform. It provides another, more fluent way for connecting scripts with the StreamZero FX Platform without the necessity to upload files directly to the platform.
A new Project will be created to showcase the capabilty of the git integration:
Create a new project
- Click on Projects in the left side menu to open drop-down and then on List Projects
- Click on +Add to create a new project
- Name the project
- Save the new project
Check the created project
- Click on the magnifying glass to open the details page of the project
Add a GitHub Repository to the created project
- Click on the Git Repositories tab
- Click on +Add to add a SSH repository URL
Copy GitHub Repo
Note that before adding your GitHub Repository to the platform, a public SSH key needs to be generated.
- Login to your GitHub account
- Go to the Repository you want to add to the project, in this use case “ferris-packages”
- Click on the the green Code button to showcase the repository URLs
- Copy the SSH URL
Paste SSH URL
- Paste the copied SSH URL from your repo
- Click save to create the repository on the platform
Note that a pair of public and private keys are generated for each repository which is safed on the StreamZero FX platform. The private key is encrypted and stored safely in the database and will never be presented to anyone, whereas the public key should be copied and added to the git repository in order to provide the StreamZero FX access to the repository and the possibility to clone packages.
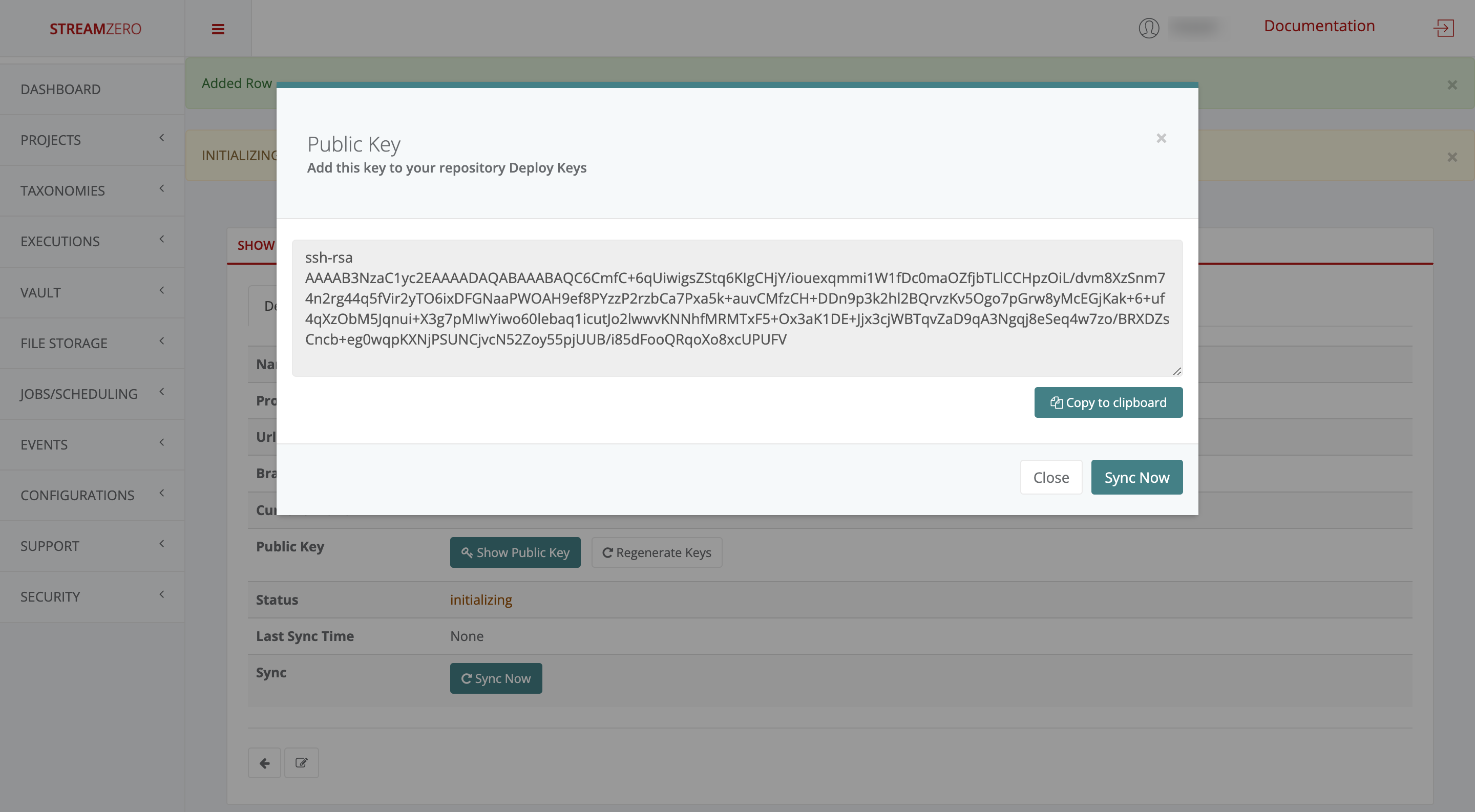
Add the public key to GitHub
- Return to your GitHub account
- Click on Settings in the top menu bar
- Click on deploy keys
- Click on Add deploy key
- Paste the generated public key
- Name the public key
- Click on Add key
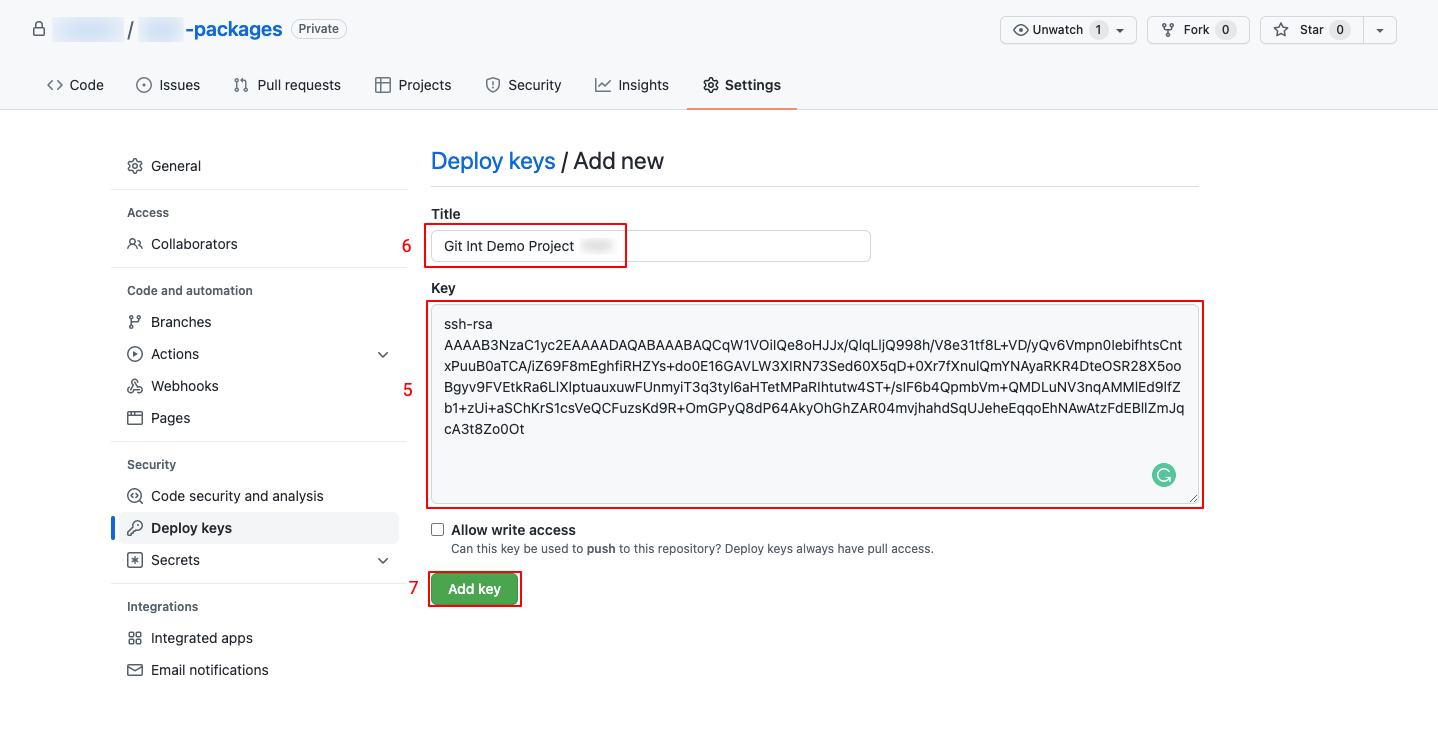
- Check the saved public key
Synchronise the repository
- Return to the StreamZero FX platform
- Click the Sync Now button to synchronise the platform with the GitHub
- Check the synchronised details page
Note that the branches (main; dev) were added and the status has changed (synced).
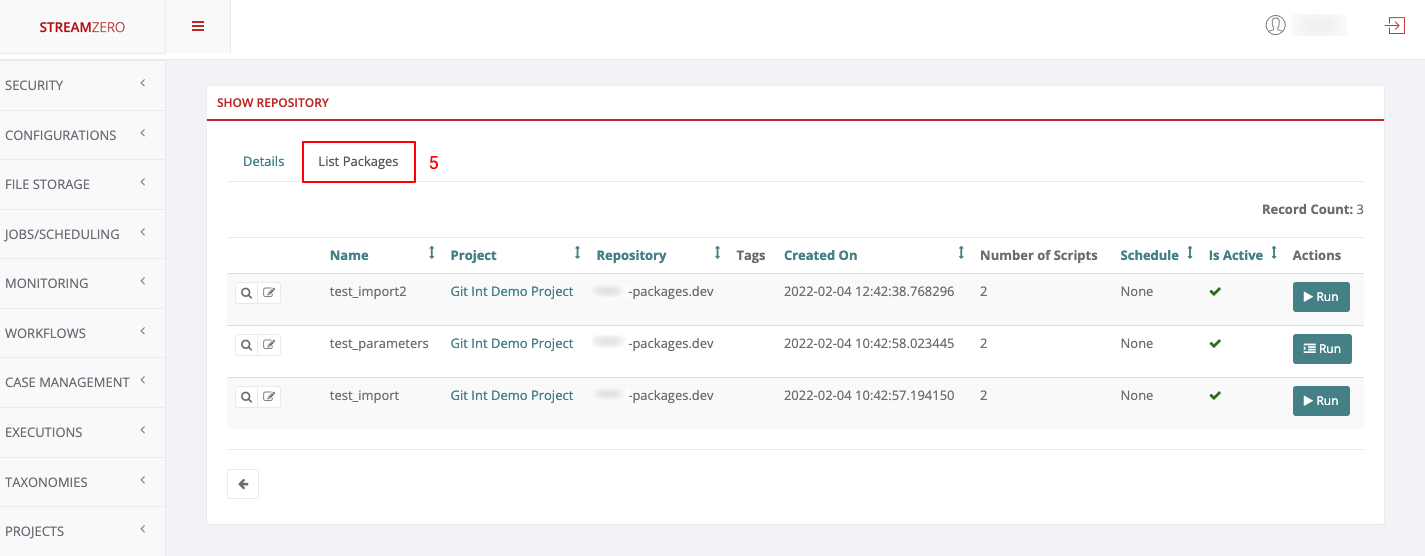
- Click on the List Packages tab to verify that the packages were imported
Change Git Branch on the platform
If a user wants to test or work on a specific branch, he can select the branch required to do so. The main branch is selected by default.
- Click on the edit button to open the Edit Repository details page
- Click in the drop-down to select the branch, in thise case “dev”
- Click on Save to save the selected branch
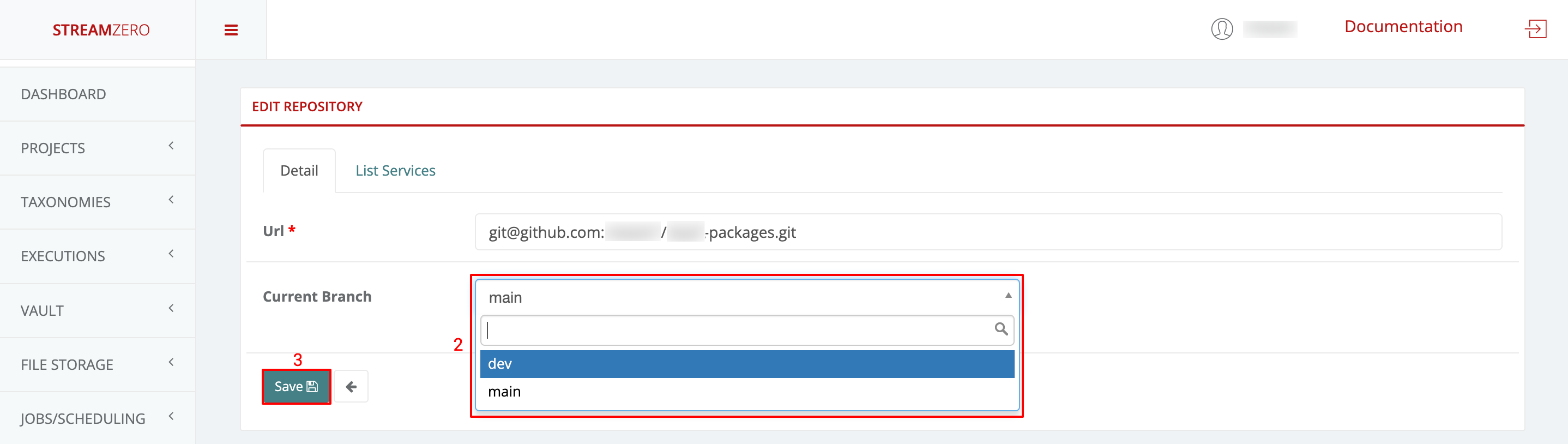
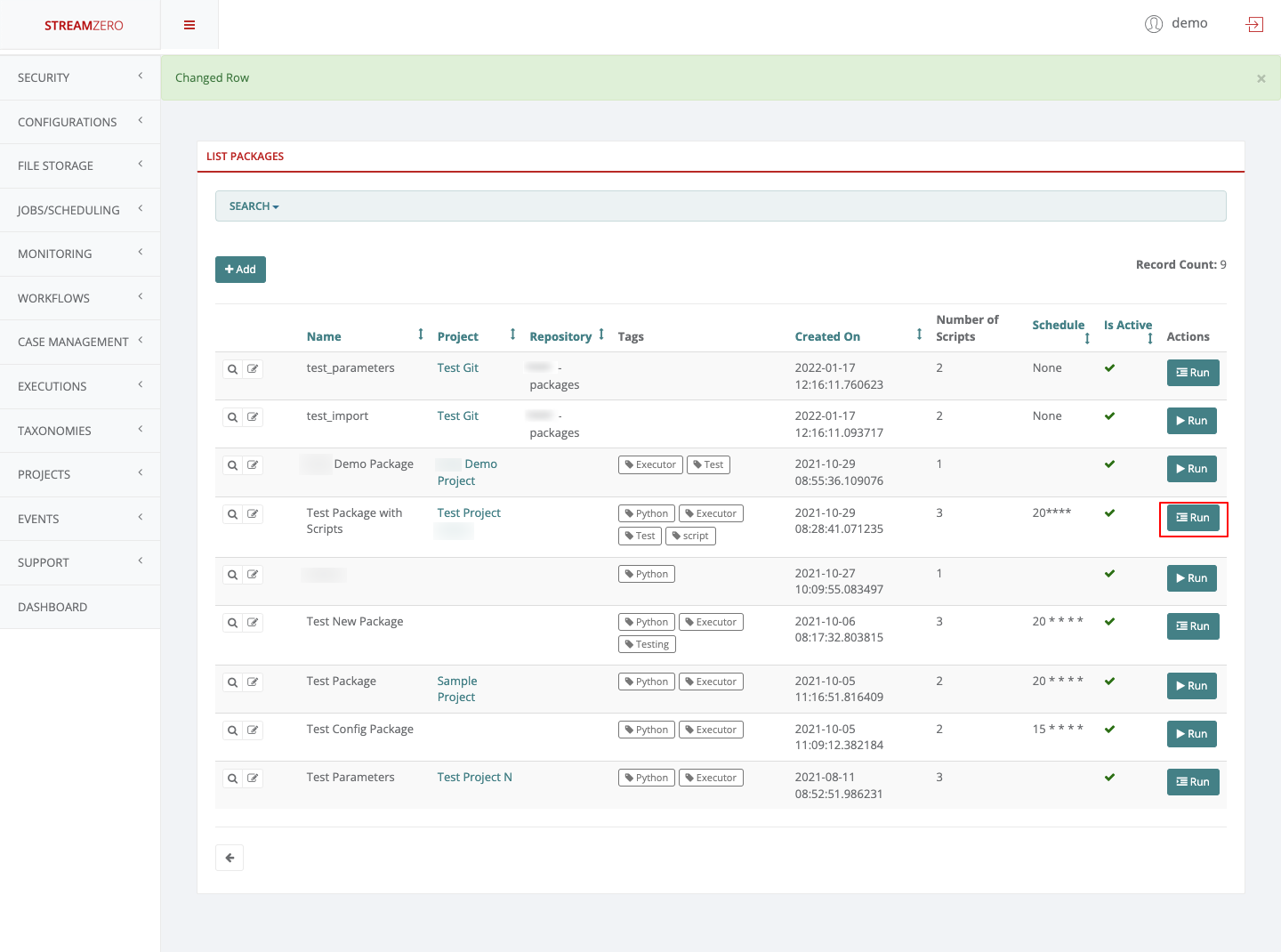
- Click on Sync to synchronise the packages from the dev branch
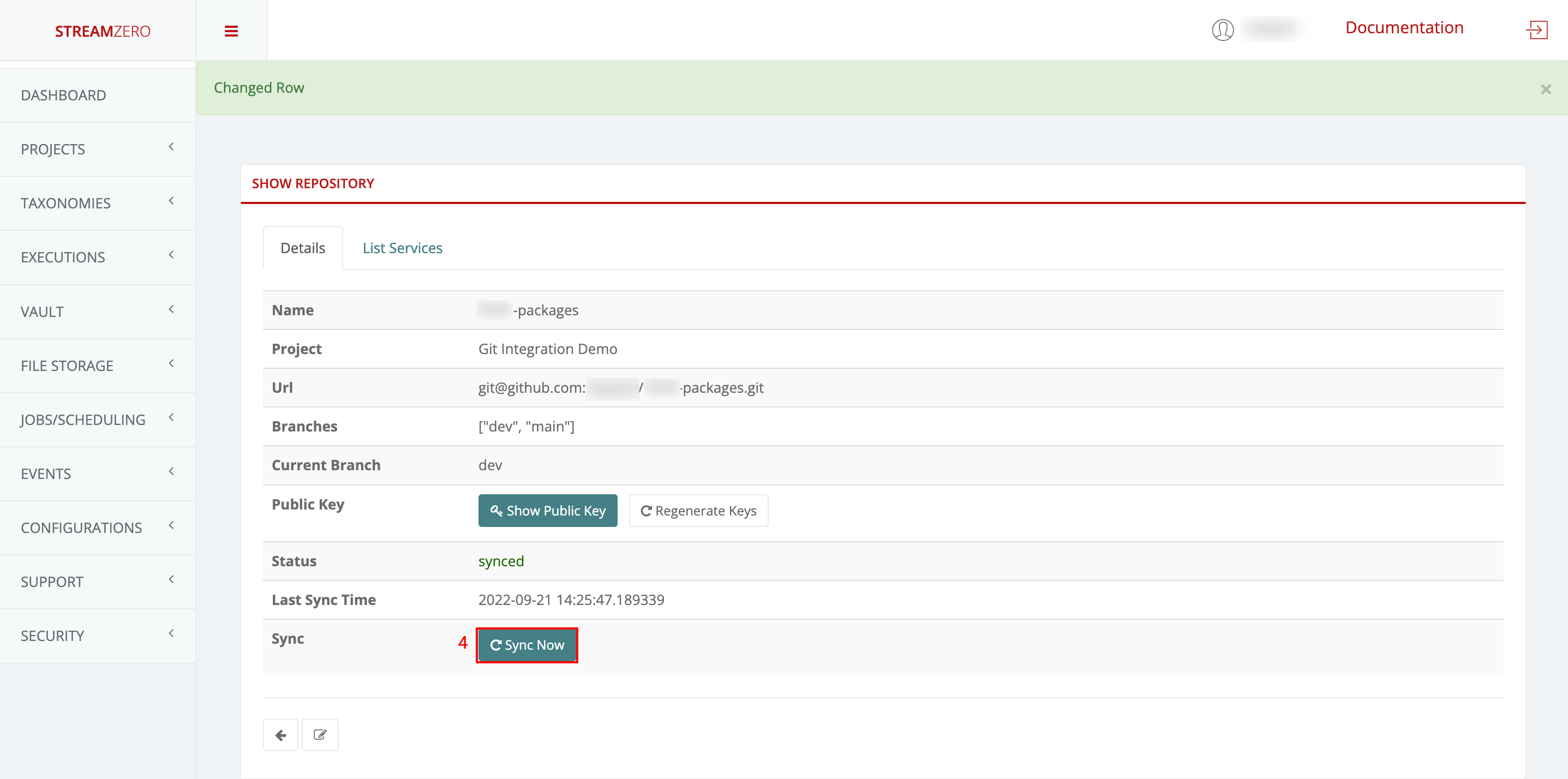
- Click on the List Packages tab to verify the packages have been synced from the dev branch
Note that a public key can be regenerated at any moment if in doubt that someone has access to it. If a new key gets generated, it needs to get added to GitHub again and synced on the platform afterwards. If the step of adding the key is missed, the synchronisation will fail. Keys can also be deleted directly on GitHub if the platform access shouldn’t be granted anymore.
12 - Event Manipulation Strategies
Events are the powerful concept at the center of the DX Platform. There are a number of strategies for using event structures. The following are a few important related topics.
- Correlation IDs
- Event Mappings
Understand the Structure
The StreamZero FX events are based on CloudEvents …
Understanding Correlation IDs
Correlation IDs are a time tested approach within the Enterprise Software Landscape. A correlation ID allows one to correlate 2 steps in a flow with eachother and identify their location in the flow sequence.
When a package receives and event the platform also passes a CorrelationID. The correlation ID is usually generated by the platform at the start of the event or assigned by the event originator. If a correlation ID does not exist then a package may create a correlation id using the library provided. The correlation id consists of 2 parts
|
|
The first part is the identifier of the unique originator id. The second part is a sequence ID which is incrementally assigned by subsequent processors. This allows the processor to indicate which the next stage of the processing is. It is left to packages to determine whether they wish to pass through the correlation ID or not. Usually it is preferable to apss the correlation ID with any event that is generated from within a package.
The following is a sample output
ABCDEF1234_01 -> ABCDEF1234_02 -> ABCDEF1234_03
Searching for a correlation ID will result in a time sorted list of runs which were triggered. By steppoing through the rsults of each stage you can easily identify the outgoing events and the results at each stage.
Leverage Event Mapping
Event mapping is the mechanism of converting from one event type to the other.
This is useful for converting from one type of even to another to trigger crossflows without altering the code of the target service.
Event mapping is done within the platform by using a configuration of event maps. Event maps describe the mapping of the attributes between the source and the target event. The also must chose between 1 of 2 strategies
- Map ONLY Mapped Fields
- Map ALL Fieds
Strategy Map only Mapped Fields
When this strategy is applied only the attributes present in the mapping file will be available in the output event.
Please note that you cannot map events to the same event type to avoid loopbacks.
Map
|
|
Source Event
|
|
Output Event
When the above map is combined with the event it will result in the name and role attributes being available as first_name and designation in the output event. But the mobile number will be stripped.
|
|
Strategy Map All Fields
When this strategy is applied only the attributes present in the mapping file will be available in the output event.
Please note that you cannot map events to the same event type to avoid loopbacks.
Map
|
|
Source Event
|
|
Output Event
When the above map is combined with the event it will result in the name and role attributes being available as first_name and designation in the output event. But the mobile number will be stripped.
|
|
13 - Logging and Monitoring
Logging and Monitoring
StreamZero FX aggregates all operational data into Elasticsearch. Most operational data and events are transported through Kafka from which it is placed in Elasticsearch by Elasticsearch Sink containers.
The following are the Kex Data and The matching Elasticsearch Indexes
Logs
Contains Logs from all applications. Elasticsearch index is XYZ
Events
All events that are transported through the ferris.events Topic are loaded into Elasticsearch Index.
Checking Logs
StreamZero Logs are in logstash format. The logs can be aggregated from the application by using the ferris_cli library.
The following is a sample log entry with extended descriptions below.
Logs are identified by the app_name attribute which provides you with an indication of the application from which it was generated.
To Filter Application Logs use the following
App_name:
Checking Events
Events are in form of cloud events. The data section of an event is schema less i.e. the data provided in the attributes may vara from event type to event type. If you require custom extractions for specific event types the best is to tap into the